前提として、データサイズが少なかったとしても、TRUEとFALSEの比率が変わらなければ、オッズ自体の値は変わりません。
- 100人いて20人がTRUE、80人がFALSEの時
- 10人いて2人がTRUE、8人がFALSEの時
どちらもオッズとしては同じ0.25になります。
オッズ: 20% / 80% = 0.25
こちらでご紹介したカテゴリー型の時のオッズ比の計算を踏まえると、データ数が少なかったとしてもオッズ比自体の計算には、ベースレベルとそれぞれの変数のオッズのみが重要になるためデータサイズは考慮されていません。
では、どういった時にカテゴリー型の変数でオッズ比が高くなるのかというと、ベースレベルと比較対象の変数のオッズに差が大きい時にオッズ比が高くなり、差が小さい時にはオッズ比が小さくなるようになっています。
例えば、下記のように研究開発がベースレベルで、人事と営業があった時に、営業の方がオッズが高くなっており、研究開発との差が大きいです。
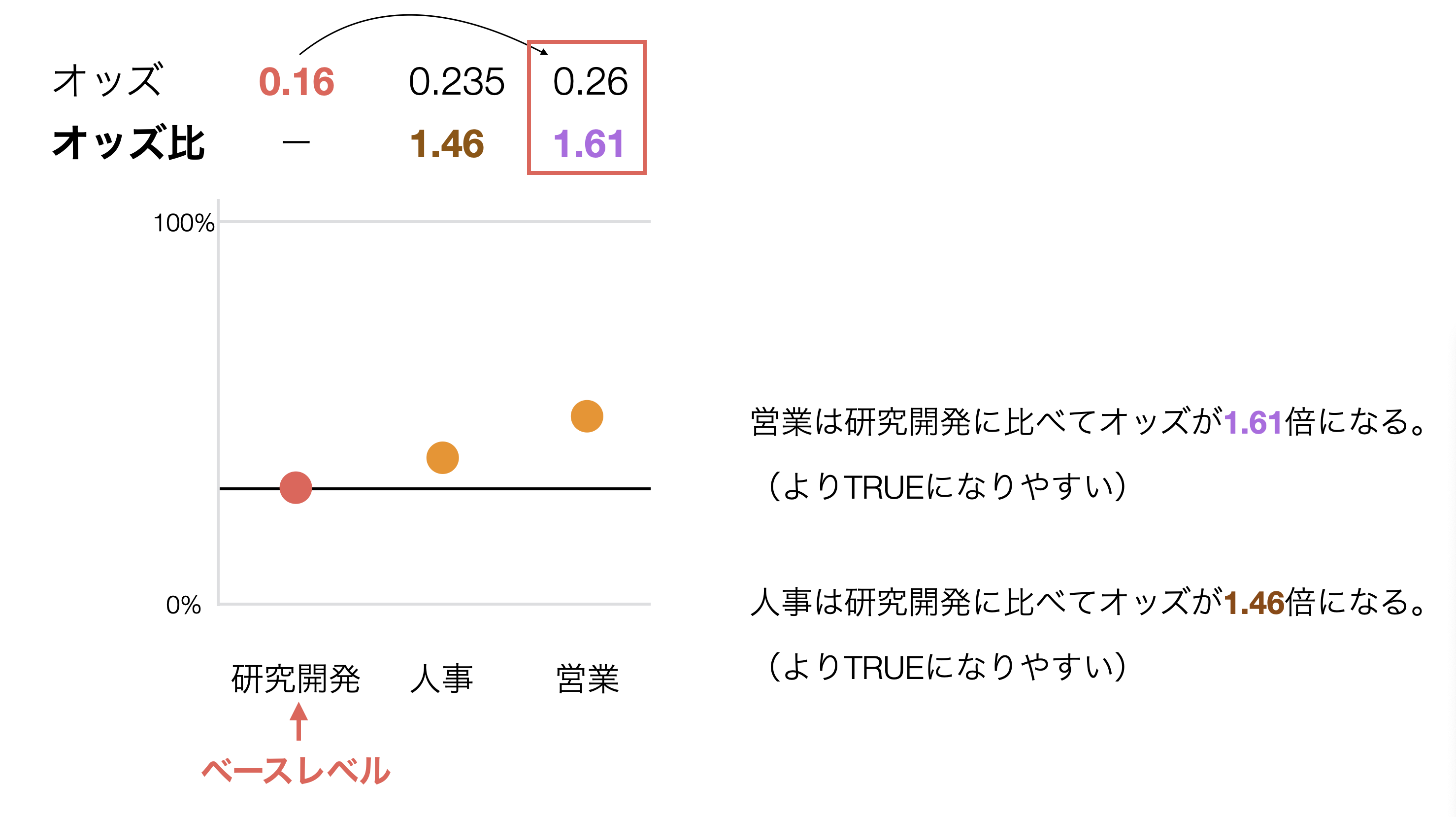
そのため、人事に比べて営業のオッズ比が高くなるという結果になっています。
一方で有意かどうかについては別となり、ロジスティック回帰ではその変数の有意性をオッズ比のP値または信頼区間として表してくれます。
下記の例では、オッズ比は1.46のため、ベースレベルである研究開発に比べて人事は離職するオッズが1.46倍となりますが、信頼区間が0.76 - 2.82と1をまたいでいます。
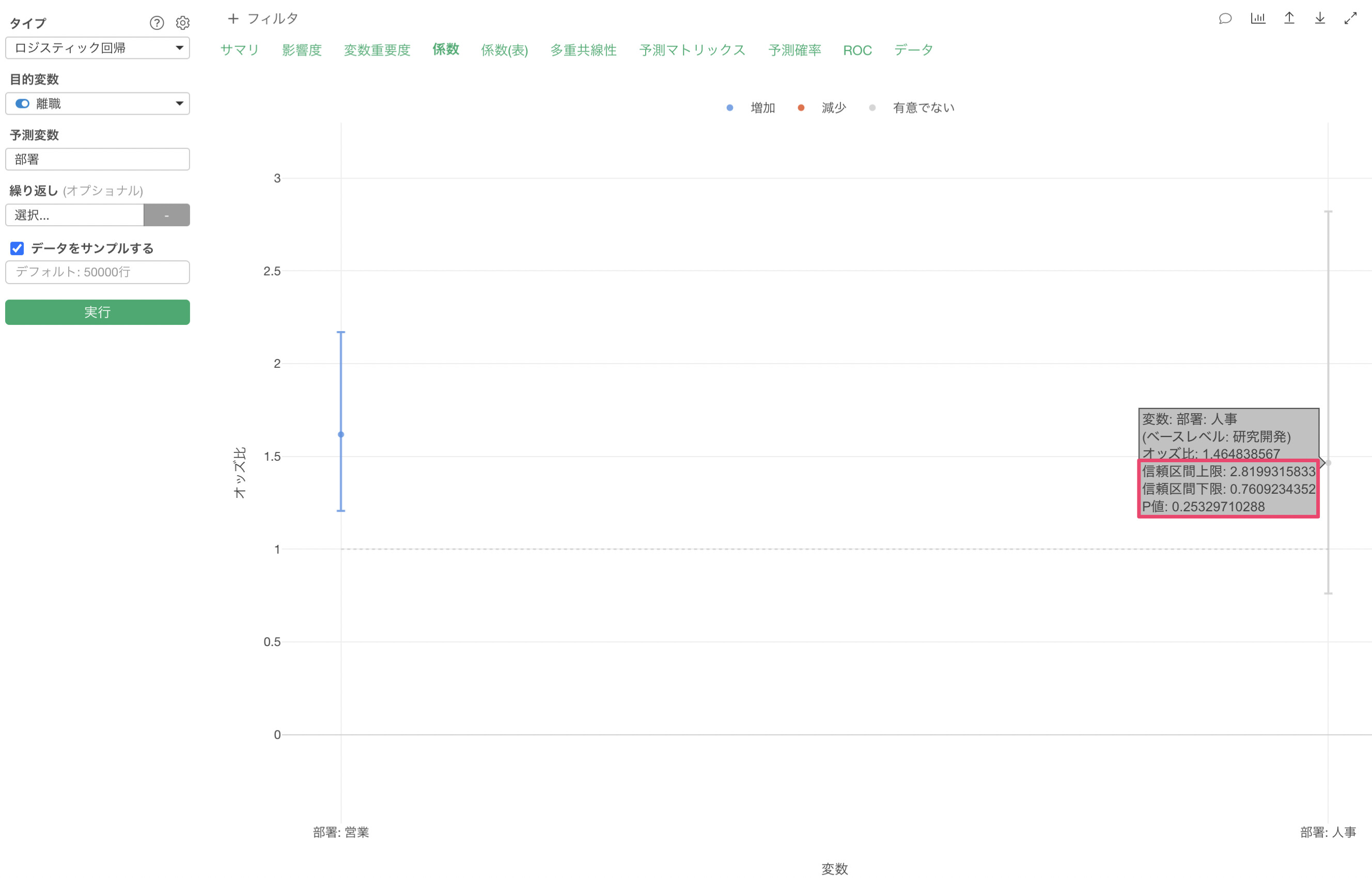
つまりはオッズ比が0.76(TRUEになりにくくなる)になるかもしれないし、2.82(TRUEになりやすくなる)になるかもしれないことです。オッズ比が1をまたいでいると、オッズが1倍、つまりは研究開発と比べて人事になったとしてもTRUEになる可能性は変わらないという判断になります。
この信頼区間は、データサイズに影響を受け、データサイズが多くなれば信頼区間は短くなり、データサイズが小さければ信頼区間は長くなります。
合わせて、P値の方でも一般的に使用される5%を基準として、有意かどうかを判断していくことが可能です。