K-Meansクラスタリングは、クラスタリングを始めるときに、ランダムにクスラターの中心を決めるところから処理を始め、観察対象をクラスターに分けていきます。
ランダムシードはそのときの初期中心の位置を決めるための「番号」のようなものです。
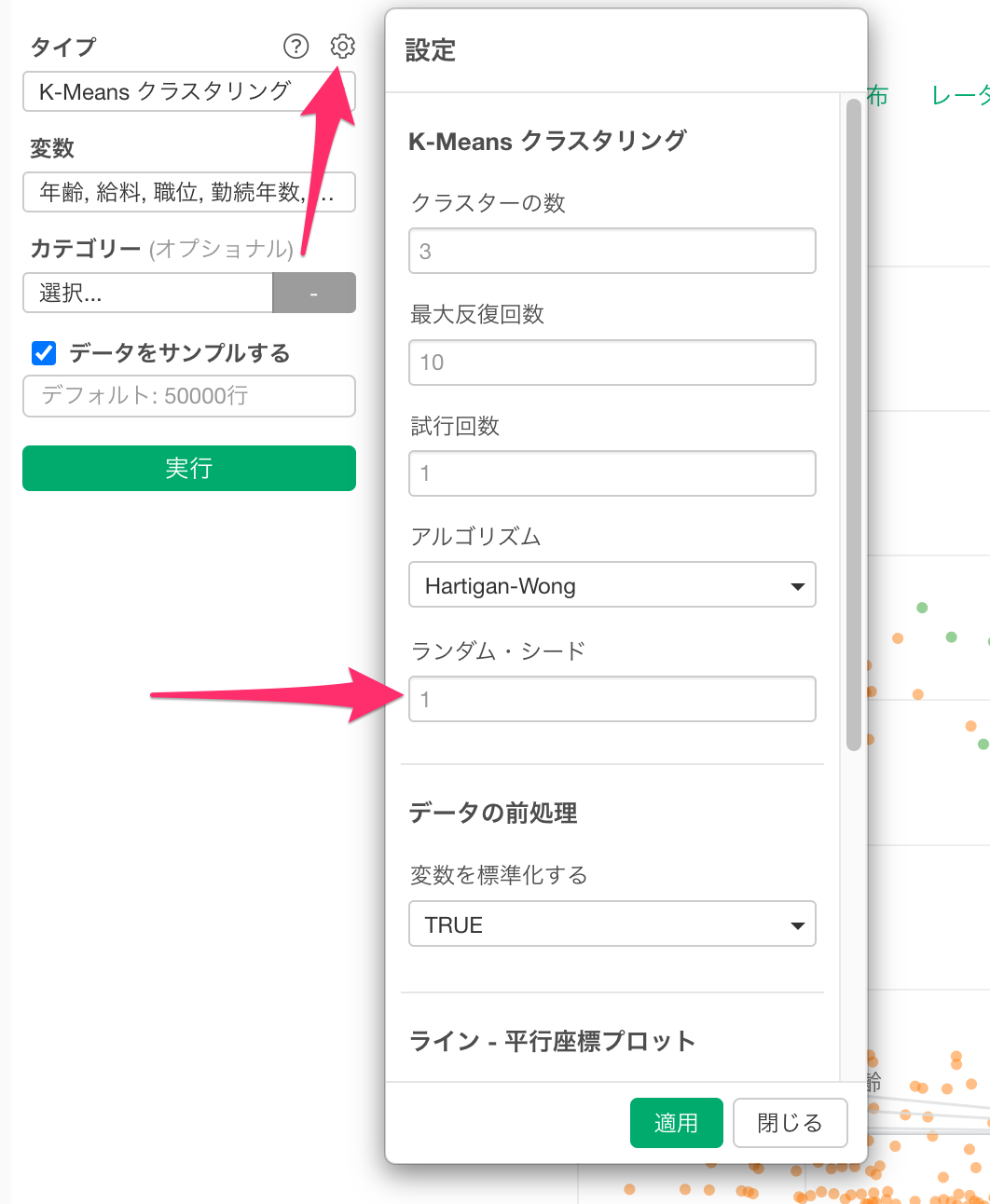
Exploratoryでは、デフォルトで同じシードを利用しているため、データとデータの順番が同じ場合、毎回同じ結果を得られることに役立っています。
ただし、MacとWindows間では文字エンコードの違いにより、シードが同じ場合でも、割り当てられる、クラスター番号が異なるなど、わずかな差異が生じることもあります。
なお、K-Meansクラスタリングに関する詳細は以下のノートをご確認ください。