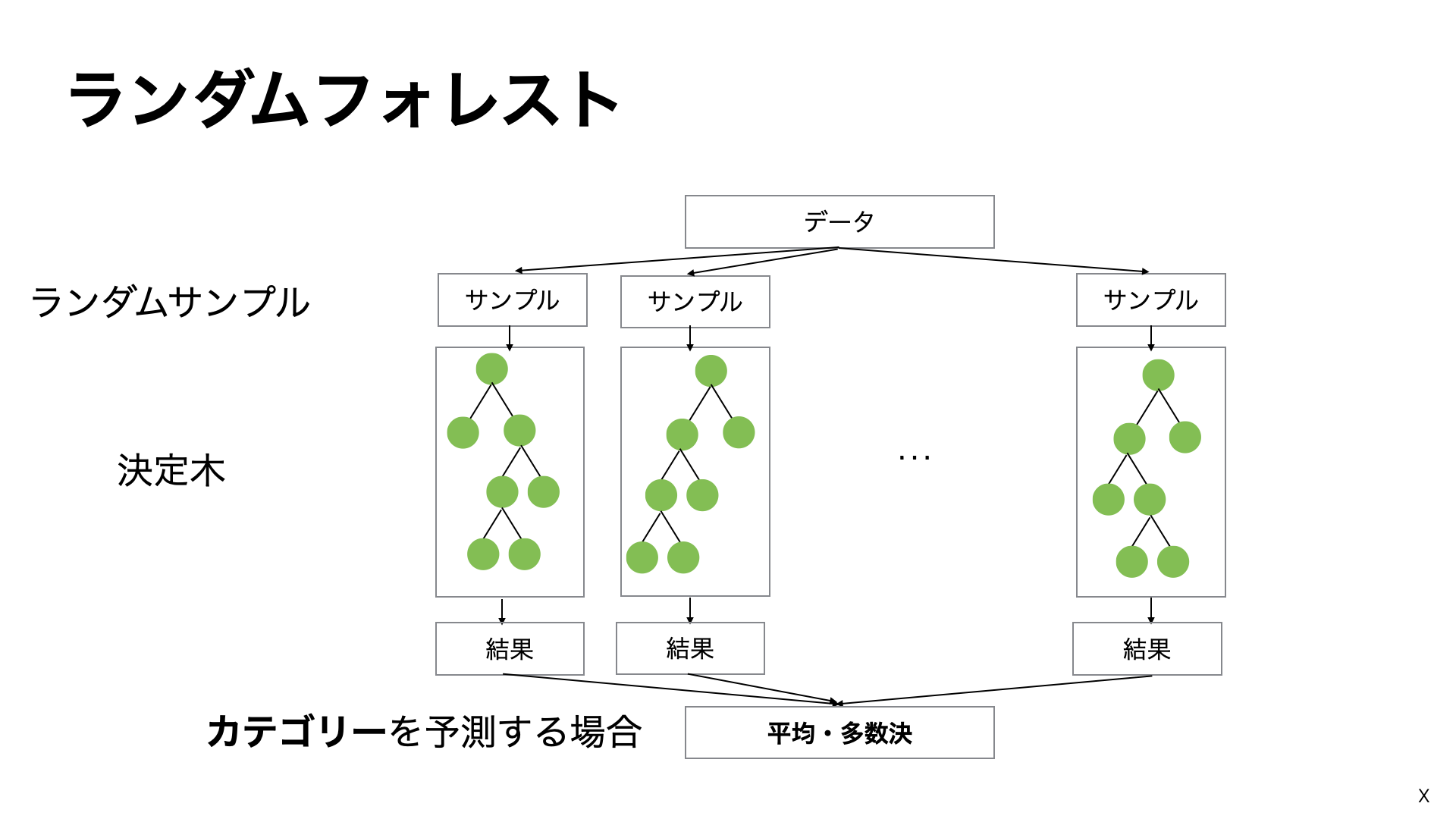
両者はともに決定木を利用したモデルになりますが、予測モデルの構築の仕方に違いがあります。
ランダムフォレストの場合、決定木を並列に作成し、それぞれ独立して学習を行い、最終的な予測を複数の木の結果を平均(数値の予測の場合)や多数決(カテゴリーの予測の場合)でまとめます。
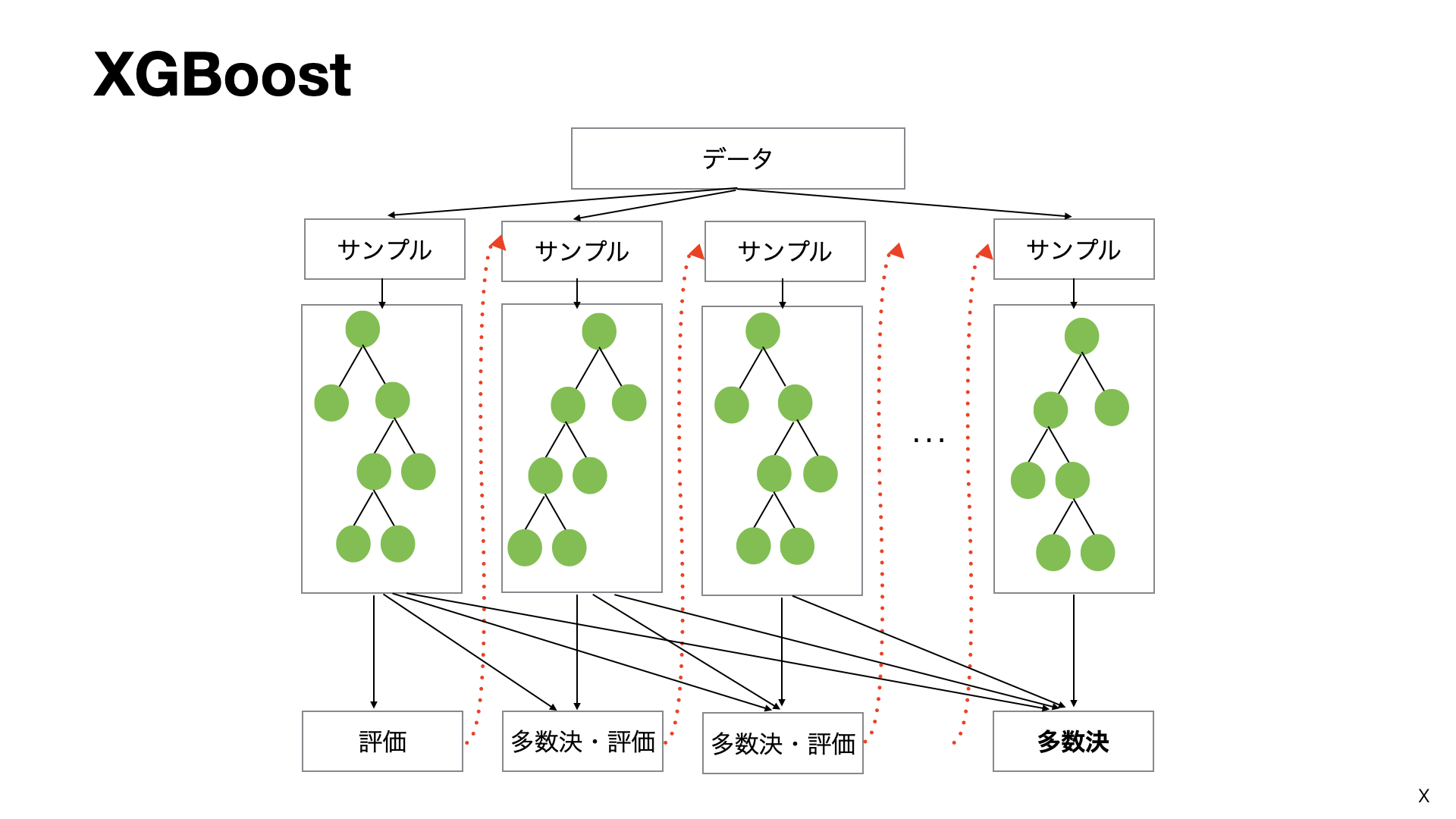
対して、XGBoostの場合、前の決定木でうまくいかなかった部分(誤差)を次の決定木で修正するような形で、順次、決定木を作成し、全ての木の出力の加重合計をもとに結果をまとめます。
両者はともに決定木を利用したモデルになりますが、予測モデルの構築の仕方に違いがあります。
ランダムフォレストの場合、決定木を並列に作成し、それぞれ独立して学習を行い、最終的な予測を複数の木の結果を平均(数値の予測の場合)や多数決(カテゴリーの予測の場合)でまとめます。
対して、XGBoostの場合、前の決定木でうまくいかなかった部分(誤差)を次の決定木で修正するような形で、順次、決定木を作成し、全ての木の出力の加重合計をもとに結果をまとめます。