Mecabを使ってワードクラウドを作ってみたいのですが、https://exploratory.io/note/2ac8ae888097/9462315684068270
このページに従ってmecabとその辞書を入れて使用すると、最新の単語あるいは専門的な単語を正しく単語単位で分割できないようです。
科学技術用語だと、「科学技術用語形態素解析辞書」https://dbarchive.biosciencedbc.jp/jp/mecab/download.html
があることが分かったので、これらを加えたいと思っています。
また、mecab-ipadic-neologdは、最新の辞書の定期的な更新を行っているようなので、これを使うことで、リアルワールドの単語の認識は高まるとも考えられます。
しかし、ここで問題が出てきて、ネットで方法を検索していろいろな記事を見るのですが、これらの辞書をインストール(?)する方法やMecabの辞書として使用する方法が具体的に分かりません。コンパイルとかコマンドなどが出てきて、作業未経験者にとっては、知識不足で手に負えていません。また、ネット上の記事は、Windows版、Linux版などのOSによる相違、辞書のエンコードによる方法の相違、R、Pythonといったプログラム言語による相違、追加する辞書自体のユーザー辞書/システム辞書としての追加、既存辞書への単語の追加なども加わって、自身の環境に応じた方法を理解しずらい状態です。
私の使用環境はwindows10です。
今想定しているのは、前出の公開されている辞書をMecabに使える辞書として導入し、Exploratoryで使用できる方法を教えていただけないでしょうか。あるいは、参考のWebページを案内していただけないでしょうか。
高橋
「いいね!」 2
sugiaki
#2
高橋さま
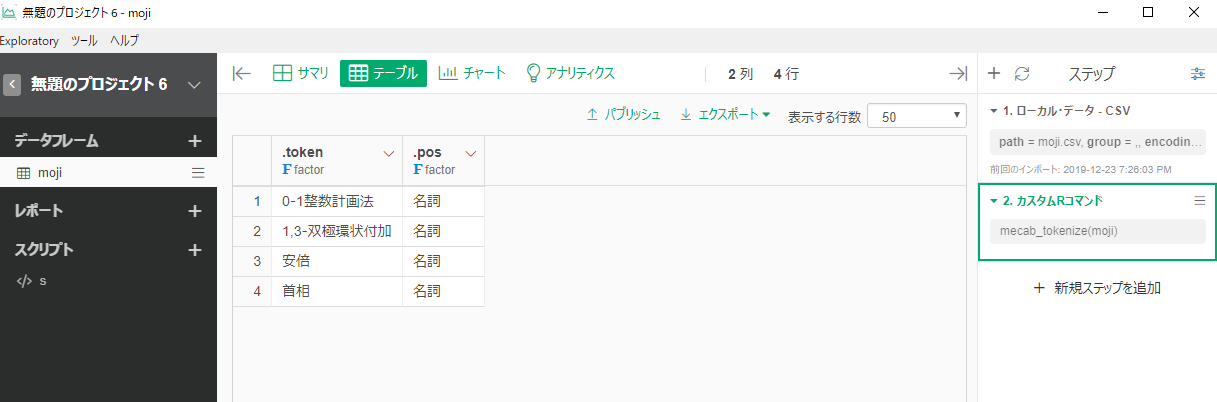
私もためしにやってみました。結論としては、辞書を入れ替えたあとに、その辞書を使って、形態素解析ができました。その方法を共有いたします。環境は同じWindows10です。
私の方法だと、辞書を変更するたびに、mecabrcファイルをいじる必要があります。
①Mecabをインストールし、RMeCabをExploratoryに読み込む方法は下記の通り進めました。
②辞書は指定されているURLからダウンロードしました。
③下記のURLに従って、辞書を「JSTシソーラス見出し語・同義語辞書」に入れ替えました。
// インストールでいじってなければ、このディレクトリに移動できるはずです
cd "C:\Program Files (x86)\MeCab\bin"
// Nikkajiは作る辞書名、mecab_nikkajiはcsvのパスなので、そこを自分の環境にあわせて変更。
mecab-dict-index.exe -d "C:\Program Files (x86)\MeCab\dic\ipadic" -u Nikkaji.dic -f shift-jis -t shift-jis C:\mecab_nikkaji.csv
// Nikkajiの部分は作った辞書名なので、1つ前で変更した辞書名
move Nikkaji.dic "C:\Program Files (x86)\MeCab\dic\ipadic"
上記をコマンドプロンプトで実行した後、下記のフォルダに移動して、
※widowsのコマンドプロンプトでcdで移動して、mecabrcを書き換えていいと思います。
C:\Program Files (x86)\MeCab\etc
mecabrcをテキストエディタで開いて、下記を;userdicの下に追記して上書き保存。
userdic=C:\Program Files (x86)\MeCab\dic\ipadic\Nikkaji.dic
あとはExploratoryでRmecabを使えば、更新後の辞書を使えると思います!
■デフォルトの辞書
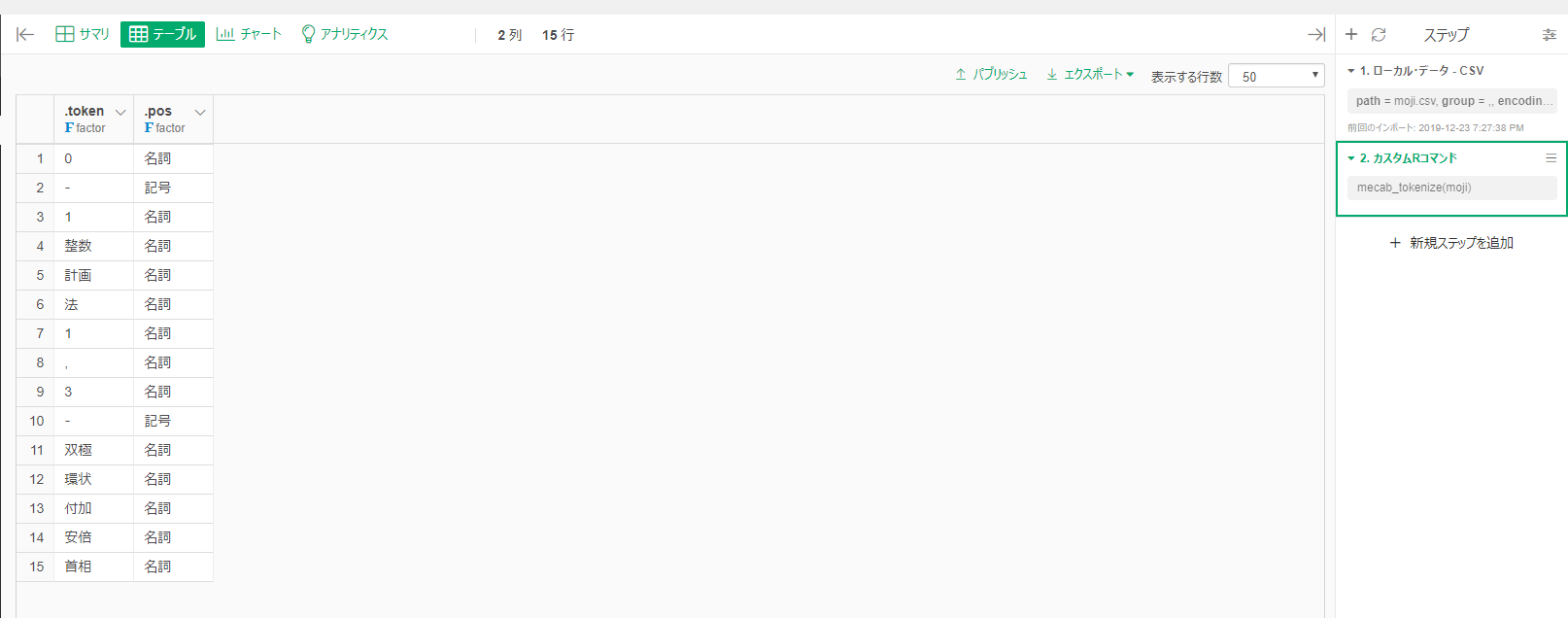
■「JSTシソーラス見出し語・同義語辞書」変更後
「いいね!」 3
わさび さん
できました!
ありがとうございます。
③のステップで、”管理者で”コマンドプロンプトを実行するのが見落としやすいですね。
疑問が出てきたのですが、
外部から導入する辞書は、ユーザー辞書に登録しているのですが、複数のユーザー辞書をMecabにて使うことはできるのでしょうか?
下記のリンクにて、「mecab-ipadic-NEologd」は 新語・固有表現に強いとあるので、こちらの方が良いと思うのですが、一方で、mecab-ipadic-NEologdに科学技術用語などの専門用語が入っていないことも考えられます。そうなると、mecab-ipadic-NEologdと専門用語辞書の両者を使うと、単語の認識は高まるのかな??と思っているのですが、どうなんでしょうか?
例えば、「ゲノム編集」という単語の場合、「ゲノム」「編集」に分割されるよりかは、「ゲノム編集」で単語として認識してもらう方が、こちらとしてはありがたいのですが。
自分でもmecab-ipadic-NEologdを入れてトライしてみます。
高橋
高橋さん
よかったです!
テキストマイニングとか自然言語処理の分野に疎くて、最新の情報ではない点、ご注意ください。
たしかRmecabの関数の引数に辞書を選択する引数があったので、そういった意味では辞書を使い分けることは可能かと思います。ドキュメントにあたってもらえれば正確かと思います!
また、最新かつ正確な回答ではないかもしれませんが、使い分けるではなく、
辞書を一度に、複数利用するのはできなかった記憶があります。
理由は、形態素解析する際に、「ゲノム解析」という単語があった場合に、
どちらかの辞書をもとに単語を分割しますが、どちらかの辞書しか使えないからです・・・
「ゲノム解析」という言葉を、
辞書Aでは「ゲノム」「解析」と分割する一方で、辞書Bでは「ゲノム解析」、辞書Cでは「ゲ」「ノ」「ム」「解析」と分割するような場合があったとすると、関数自体がどの辞書を優先するのか判断できないので、複数の辞書を柔軟に使い分けるというのが、仕組み上できない。
なので、このような場合に自分で辞書A、B、Cをマージして、自分専用の辞書を作るということを、言語系のデータ解析者はやっていると聞きました。
あくまでも私の乏しい知識の中での話なので、今はどうなっているかわかりません・・・。
意図を組み違えていれば、申し訳ありません・・・
追記:調べてみるとユーザー辞書に追加していけば、場当たり的に対応できるのかもしれません・・・
わさびさん
意図を的確に把握されていらっしゃいます。
複数の辞書を使用できたとしても、少し時間がたてば、どれを導入しているのか不確定になるので、やはり、そこは避けて、完璧は求めず1つの辞書である程度許容できる方法を探ろうかと思っています。
色々とネット記事を見ていると、mecab-ipadic-NEologdは、様々な単語を収録している様子なので、専門用語もある程度カバーしている可能性が高いように思うので、mecab-ipadic-NEologdをユーザー辞書に登録して評価してみるのが現在は妥当な気がしています。
やってみるしかないって(腹はくくった!)状況です。
ダウンロード、PATH、環境設定などで苦労しそうですが、ここに記録を残そうかなと思っています。

「いいね!」 1
mecab-ipadic-NEologdの導入を下記のサイトに沿って行いました。辞書のダウンロード、辞書の移動はできました。
できたという根拠は、管理者権限のコマンドプロンプトにおいて、"done"が表示され、作り出したNEologd.20191212.dicがwindowsでも見れるという判断基準です。
NEologd.20191212.dicは、mecabrcにおいてユーザー辞書として登録しました。
実際に機能するかをExploratoryで確認したところ、機能していない状態でした。
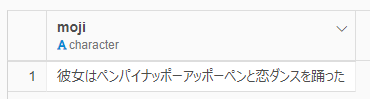
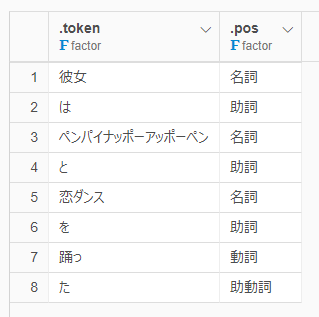
例文として、「彼女はペンパイナッポーアッポーペンと恋ダンスを踊った」を指標にしました。https://engineering.linecorp.com/ja/blog/mecab-ipadic-neologd-new-words-and-expressions/
上記のサイトでは、「恋ダンス」が一つの単語として認識されているのですが、実際は「恋」「ダンス」に分かれてしまってます。
ユーザー辞書ではなく、システム辞書にNEologd.20191212.dicを登録するのかと思い、試したのですが、よくわからず、頓挫しました。
コマンド等に全く詳しくもなく、また、形態素解析と mecab-ipadic-NEologdにも詳しくないので、これ以上は、分からなくなりました。
mecab-ipadic-NEologdは定期的なアップデートがかかるようなのですが、この特徴を利用できる設定にできているのかも分かりません。

適切にお伝えできていないかもしれませんが、私では無理そうだということはわかりました。
高橋
高橋さま
下記のサイトをもとに、私もmecab-ipadic-NEologdの導入を試してみました。
結果としては、導入できました。高橋さまと同じく、例文として「彼女はペンパイナッポーアッポーペンと恋ダンスを踊った」を指標にしました。「新語・固有表現に強い「mecab-ipadic-NEologd」の効果を調べてみた」と分割後は同じです。
この「WindowsでNEologd辞書を比較的簡単に入れる方法」に書いている方法に従っただけなので、特別なことはしてません。
Git、コマンドプロンプト、環境変数PATHとかややこしいことは多いですが、もしよかったら試してみてください!
よろしくお願いいたします。
「いいね!」 1
わさびさん
以下、教えてください。
「 WindowsでNEologd辞書を比較的簡単に入れる方法」
を私も参考にしていたのですが、最後の「 UTF-8辞書の作成」をわさびさんは実施されましたか?(私は、Mecabのインストールの際に、Shift-jisを選択していたので、不要だろうと判断してやっていなかったです。)
高橋
高橋さん
今回は必要ないので「UTF-8辞書の作成」はしてません。なので、「 mecabrcファイルの編集」までです。
変更した点は、リンク先にも記載がある通り、git cloneした時点のリポジトリの中にあるデータの日付に合わせる、というところだけです。
よろしくお願いいたします!
わさびさん
できました!
「恋ダンス」と認識しました!
解決しないといけない点がいくつかあったので、記録しておきます。
ご指摘のように「UTF-8辞書の作成」はせずに、「 mecabrcファイルの編集」まででOKでした。
1点目
mecab-ipadic-NEologdをダウンロードするディレクトリは、Cドライブ直下にしました。管理者権限のコマンドプロンプトを開いた場合、C:\Windows\System32以下にフォルダが作成されるのですが、コンパイルのステップで、「ファイルが見つからない」といったエラーが出たりしたためです。本当にこの原因かわからないのですが・・。
2点目
C:\Program Files (x86)\MeCab\etc 内のmecabrcファイルに
初期値「; userdic = /home/foo/bar/user.dic」に対して
「userdic = C:\Program Files (x86)\MeCab\dic\NEologd\NEologd.20191212.dic」
を置換する際に、“userdic =” の前にセミコロンが残っていると機能しないこと
でした。
当たり前のことかもしれないのですが、コマンドを触ったことない者にとっては、気付かないことでした。(セミコロン一つで!?まじか~)
次は、実際の短文を使ってみます。
高橋
「いいね!」 1
自分のメモになりそうなのですが、
ユーザー辞書は、複数登録できそう。
「いいね!」 2