カイ二乗検定で、サンプル数の見積もりを試しています。
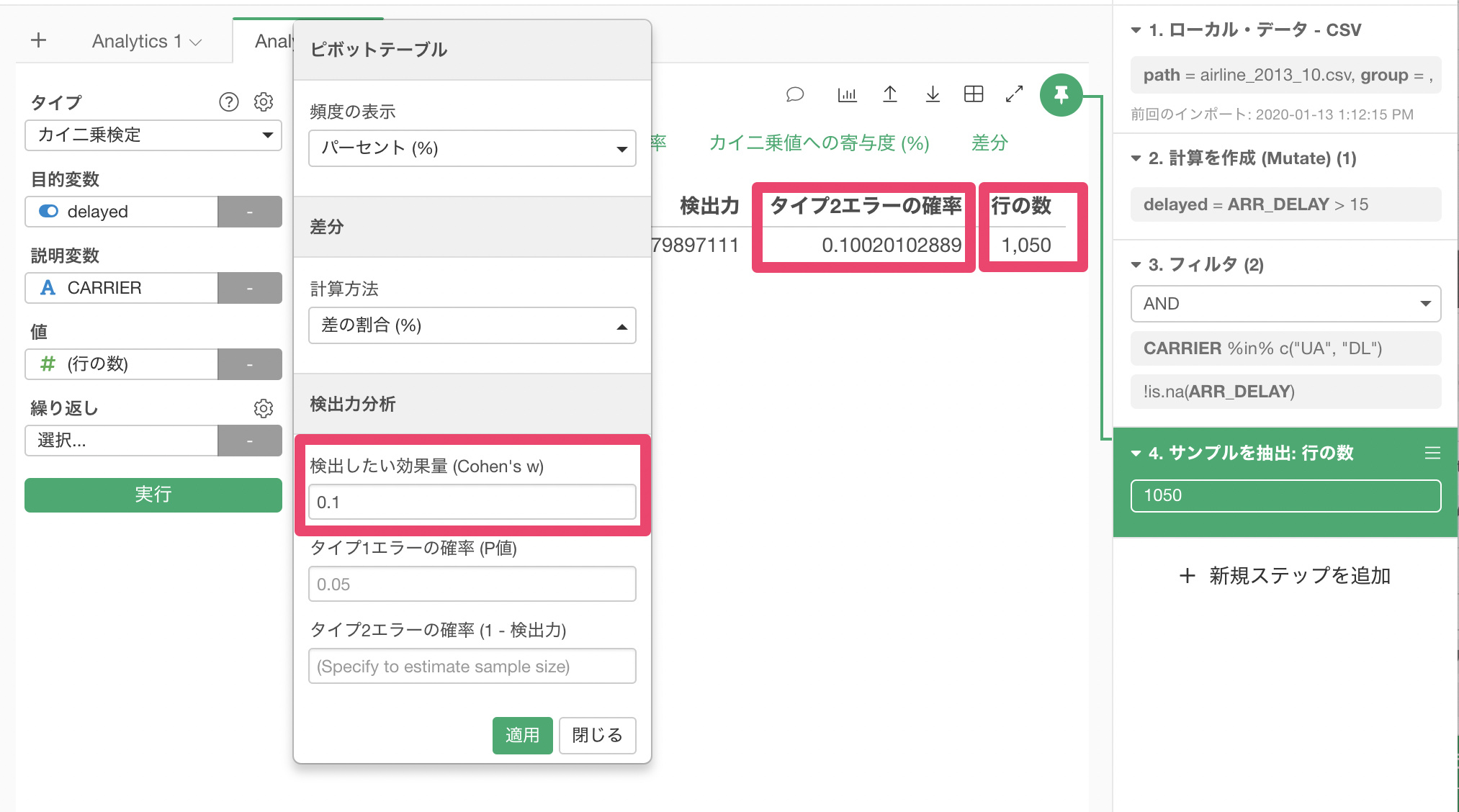
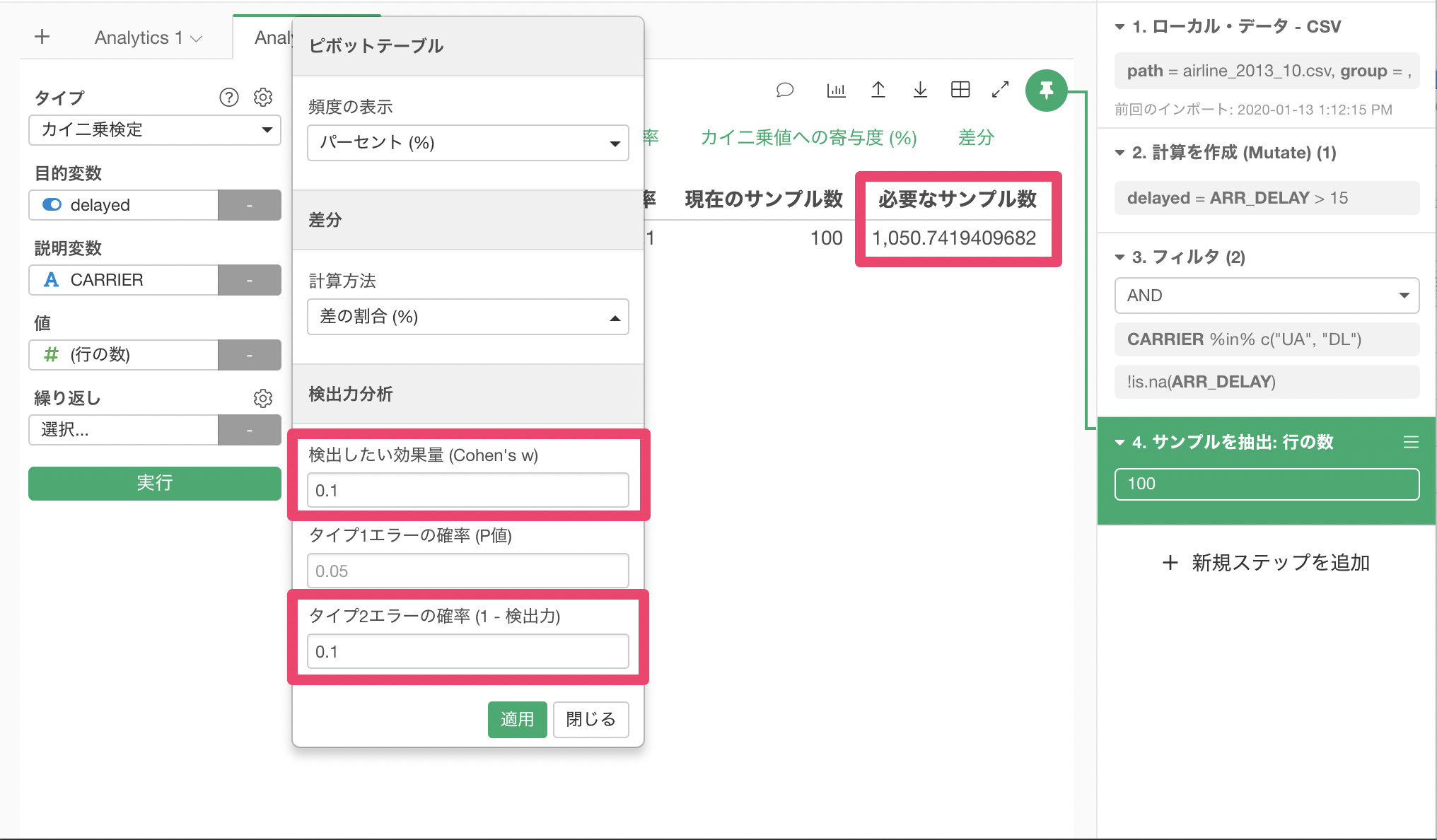
検出したい効果量(Cohen’s w)0.1で、タイプ2エラーの確率を0.1以下に抑えたいとして、必要なサンプル数を見積もると、 1050.74行と出ました。
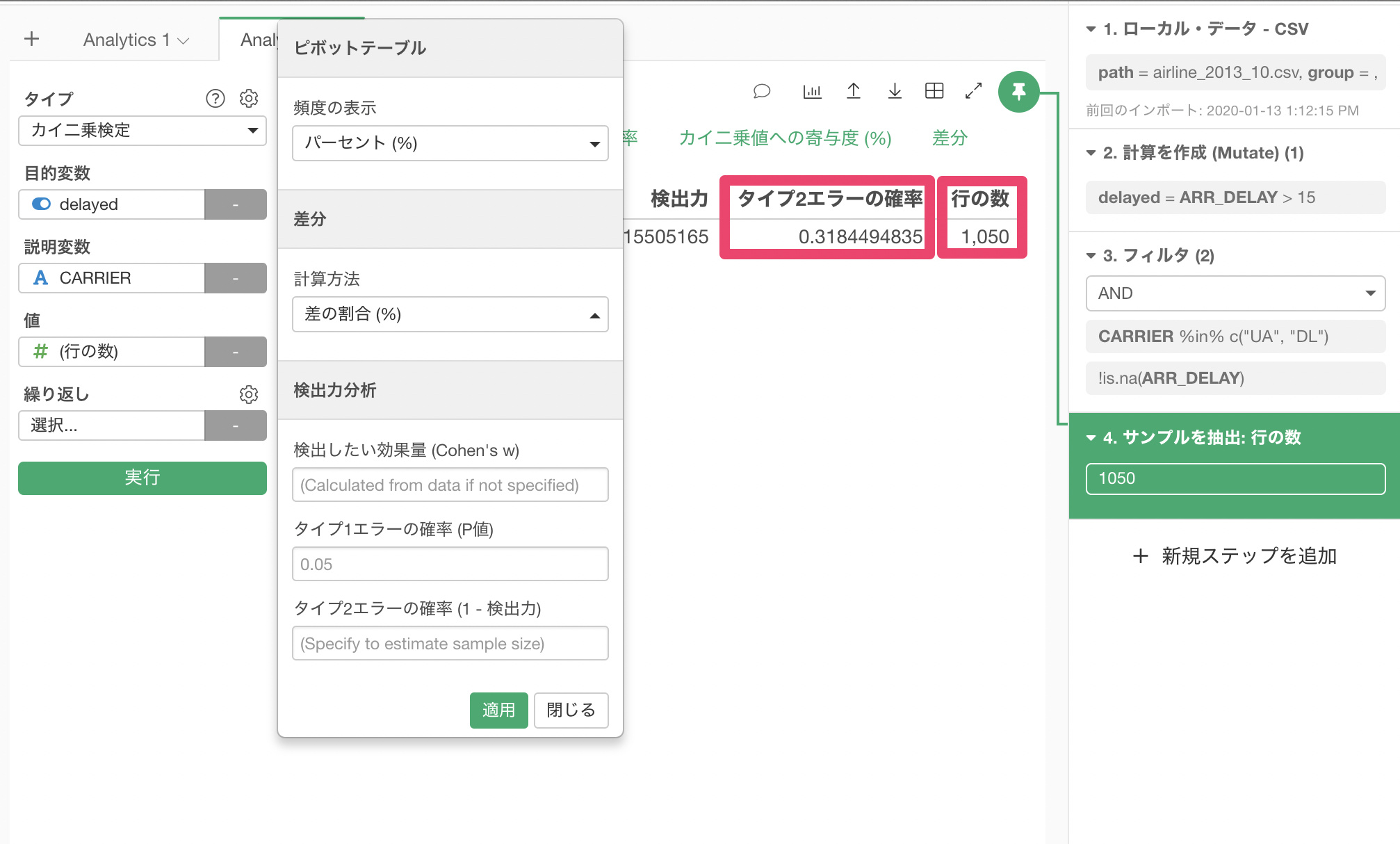
そこで、1050行のデータを用意して、再度検定を走らせてみましたが、タイプ2エラーの確率は、0.318と、0.1以下に抑えられていません。何が問題なのでしょうか?
※カスタマーサポートに寄せらたお客様からの質問を、個別の事情を伏せて一般的な質問に書き換えた上で共有させて頂いたものです。