「テキストデータの加工」における「テキストの単語化」
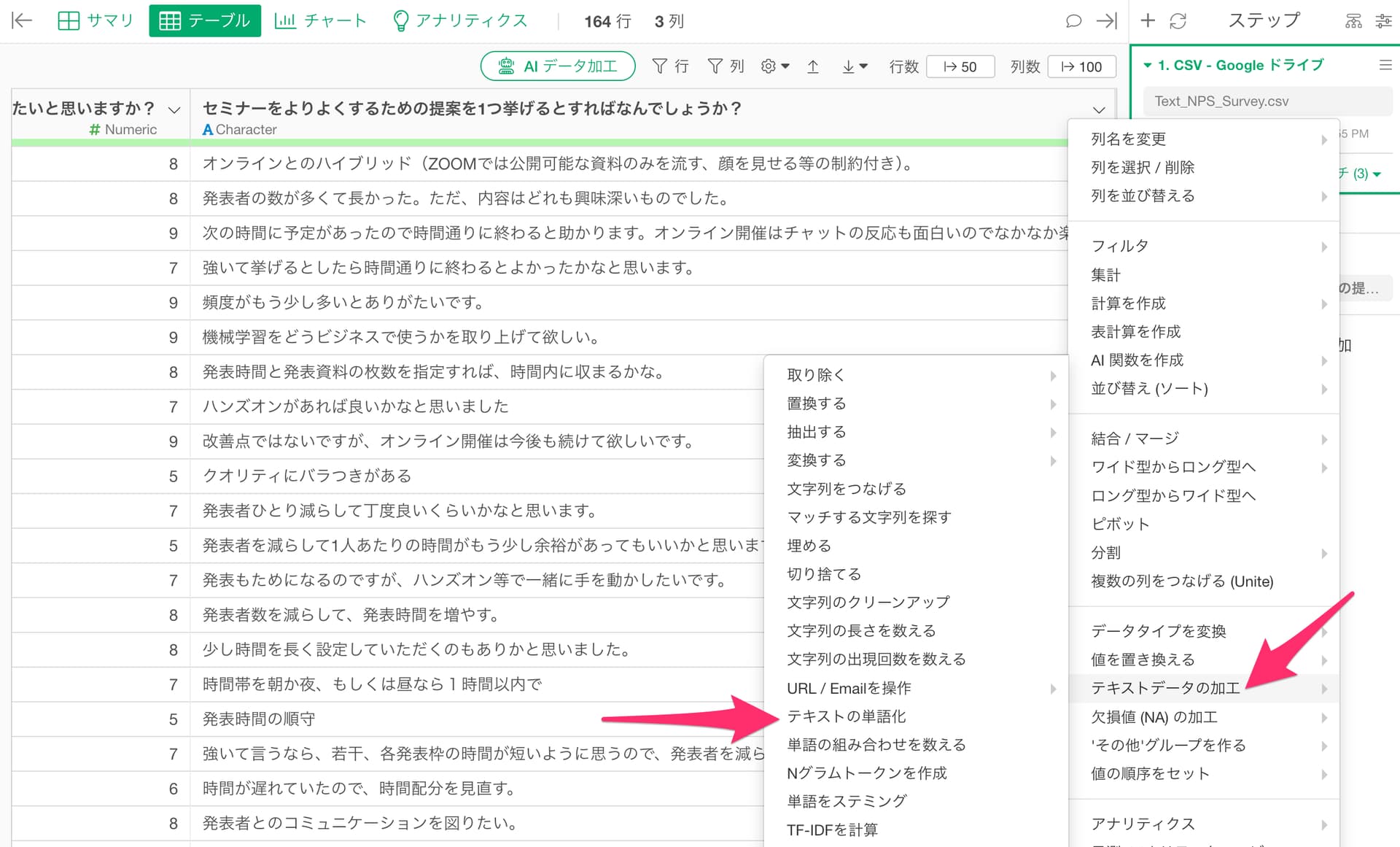
UIから利用できる「テキストの単語化」機能は、Rの stringi パッケージを使用しており、ICU(International Components for Unicode)と呼ばれる仕組みで文字列を分割し、単語に分ける処理を実行しています。
ストップワードの処理にはSlothLibという日本語辞書をベースにExploratory社が編集したものを利用しています。
バージョンの確認方法
stringi パッケージのバージョン確認
stringi のバージョンはご利用のExploratoryデスクトップのバージョンによって異なります。以下の手順で確認してください。
まず、Exploratoryデスクトップを開き、プロジェクトの一覧からR パッケージを開き、「システム」タブをクリックします。
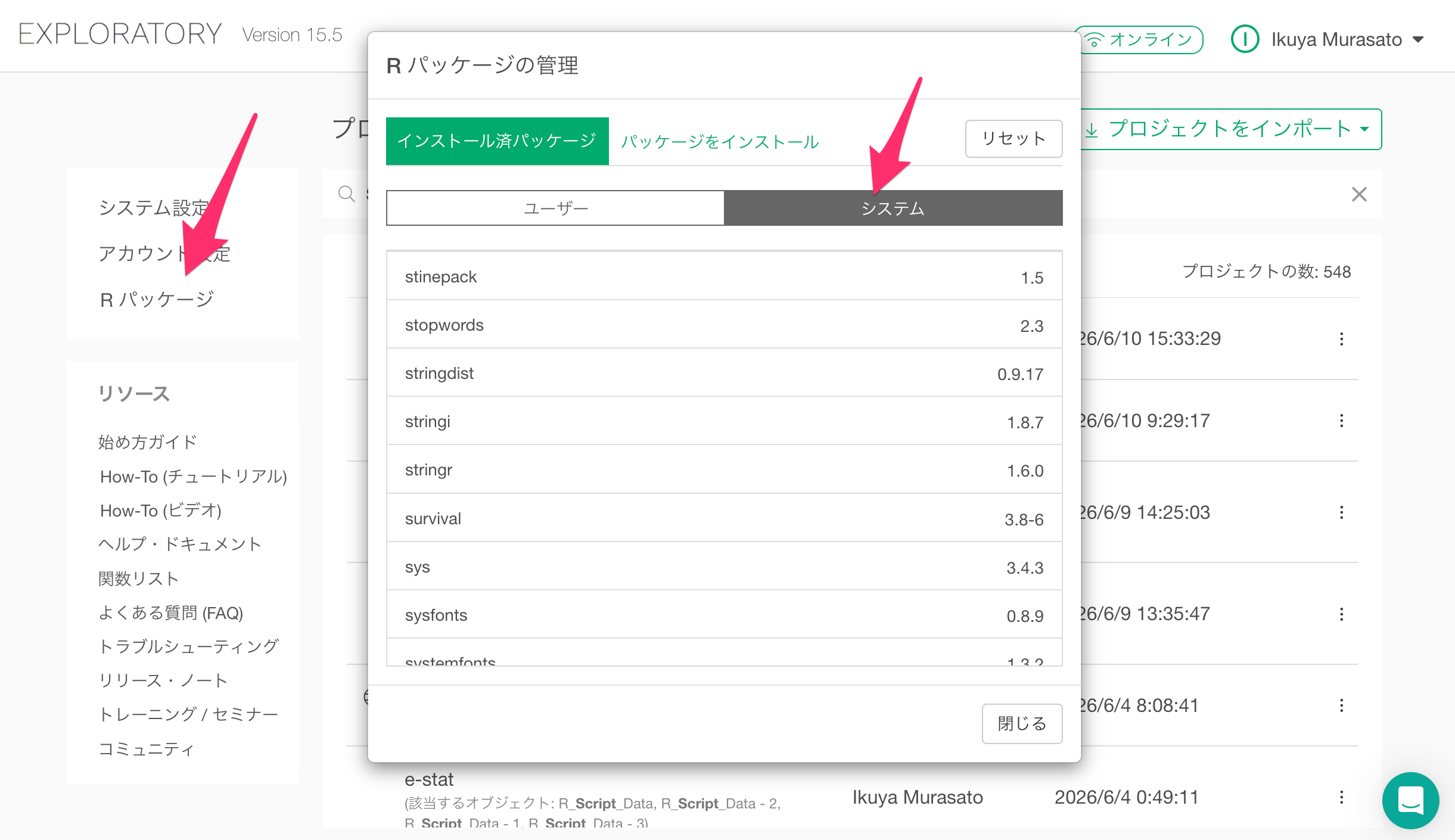
Rパッケージの一覧から stringi を見つけ、バージョンを確認してください。
MeCabを使った形態素解析
以下のリンクで紹介しているように、ExploratoryではMeCabとRMeCabをインストールして、単語に分割することも可能です。
- RMeCabを使った日本語テキスト分析 - リンク
「テキストの単語化」とは別に、MeCabを使った形態素解析を行っている場合、ご自身でインストールされている環境に依存します。
RMeCab パッケージのバージョン確認
なお、RMeCabのバージョンはExploratoryの内部から確認が可能です。
まず、Exploratoryデスクトップを開き、プロジェクトの一覧からR パッケージを開、「ユーザー」タブをクリックします。
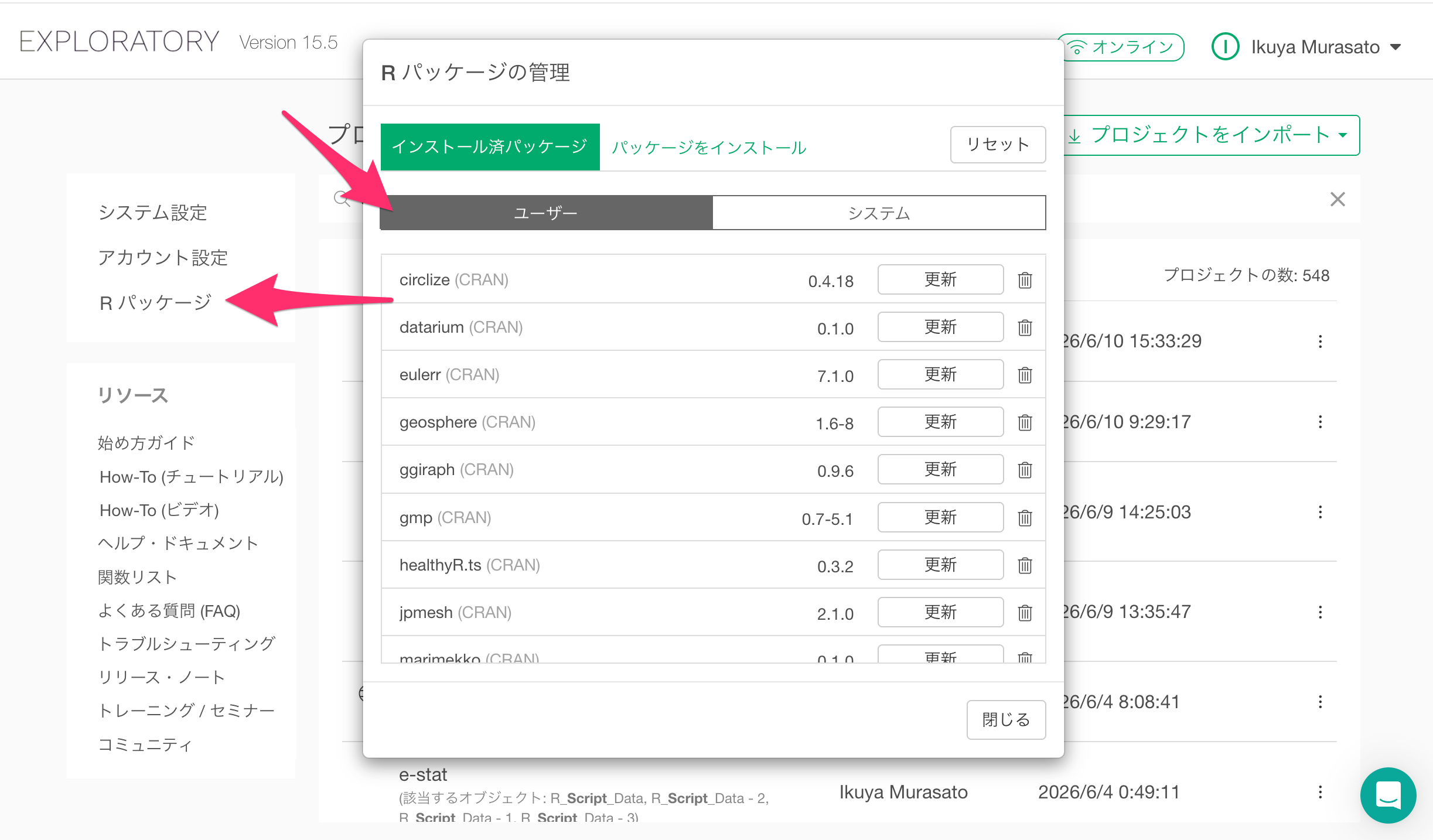
このときご自身で、RMeCabパッケージをインストールしていない場合は、パッケージ情報は表示されませんのでご注意ください。
Exploratoryのバージョンを確認したい場合
Exploratoryで利用しているRのバージョンを確認されたい場合、
ご利用のExploratoryのバージョンをお知らせいただければ回答いたしますので、サポートまたは、チャットまでお問い合わせください。