例えば、あるデータフレーム(df1とします)に「年月」がカラムとしてあり、
"202001"という値が入っていたとして、
その値を含むようなフォルダ(例えばc:\data\202001)からデータを拾ってきて
別のデータフレーム(df2とします)をRスクリプトで作るのに、
setwd(“c:/data/202001”)
というような形でフォルダを指定するとします。
しかしこれでは、元のdf1のデータを更新し年月が"202002"に変わった時、
Rスクリプトそのものをc:/data/202002、と変更する必要があります。
これを、df1のインポート後、ただdf2の再インポートの操作を行うだけで
動的に変更できないものかと考えています。
そこで、パラメータの機能を使い、df1の年月をパラメータyyyymmとして、
df2のRスクリプトによるフォルダ指定を
setwd(paste(“c:/data/”,@{yyyymm},sep=""))
というような形にしてみたのですが、
df1のデータを更新しただけではパラメータそのものは変更されず
一度パラメータの設定画面にまで踏み込んで
もう一度値を拾い直さないといけないようなので
スクリプトそのものを変更するのとあまり手間が変わりません。
なにか良い方法はないでしょうか。
「いいね!」 2
@Yasuhiro_Yatsuu さん
完全に質問の意図が組みきれているかどうか自信がないので、的はずれな回答になるかもしれませんが、 よければ参考にいただけますと幸いです。
・前提
①あるデータフレームdf1に「年月」がカラムとしてあり、"202001"という値がある
→下記では、/Users/aki/Desktop/dir_source/df1.csvとします。ファイル構成は下記の通りです。
dir_source/
└── df1.csv
②このdf1の年月というカラムの値"202001"をもとに、読み込むフォルダを決定する。
→下記では、/Users/aki/Desktop/dir_targetがこれにあたります。ファイル構成は下記の通りです。
dir_target
├── 202001
│ ├── df_202001_01.csv
│ ├── df_202001_02.csv
│ └── df_202001_03.csv
└── 202002
├── df_202002_01.csv
├── df_202002_02.csv
└── df_202002_03.csv
・実現したいこと
①df1の年月から202001という値を取る。
②この"202001"を使い、**/**/**/202001のフォルダのデータをExploratory上でdf2に読み込む
↓
↓時間が経過して、年月の値が変わる
↓
③df1のデータを更新し、年月が"202002"に変わる
④この"202002"を使い、**/**/**/202002のフォルダのデータをExploratory上でdf2に読み込む
↓
↓時間が経過して、年月の値が変わる
↓
⑤df1のデータを更新し、年月が"202003"に変わる
⑥この"202003"を使い、**/**/**/202003のフォルダのデータをExploratory上でdf2に読み込む
↓
以降繰り返し
・実装
①カスタムスクリプトに下記を保存
switch_read <- function(dir_sorce, dir_target) {
df_source <- readr::read_csv(dir_sorce)
# もとのデータフレームがどのような物なのかわからないので、
# とりあえず、なんらかの方法で"202001"という文字列がとれる前提
tag <- df_source %>% dplyr::pull(yyyymm)
path <- stringr::str_c(dir_target, tag)
dir_csv <- list.files(path = path,
full.names = TRUE,
pattern = "*.csv")
df <- sapply(X = dir_csv,
FUN = readr::read_csv,
simplify = FALSE) %>%
bind_rows(.id = "id")
return(df)
}
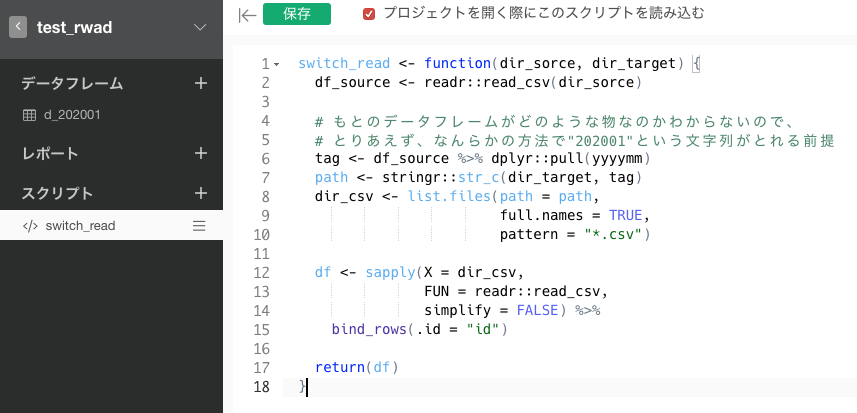
②データを読み込む際に、df1の年月の"202001"という値を使って自動でフォルダを指定して読み込む関数switch_read()をRスクリプト・データフレームで利用する。
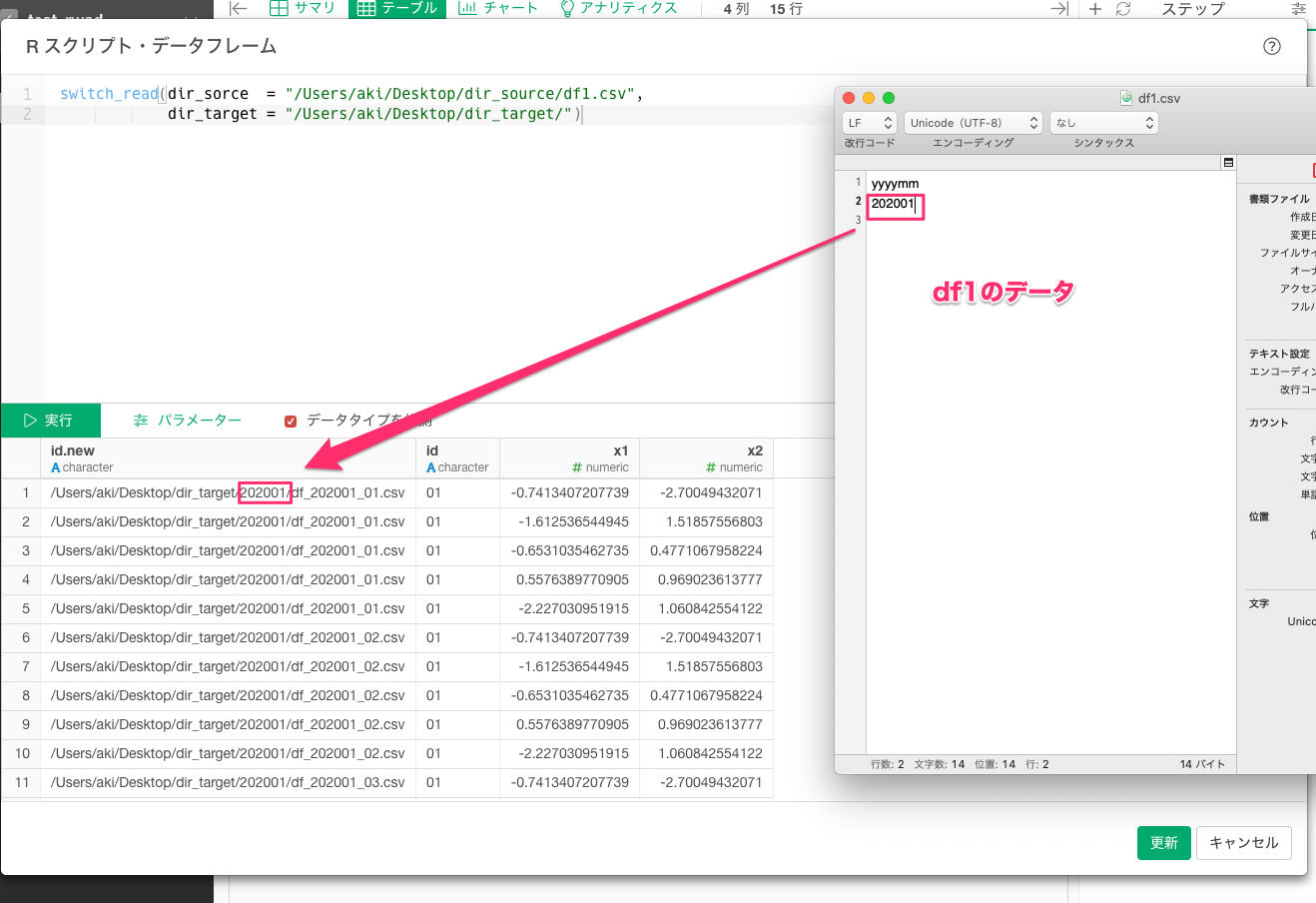
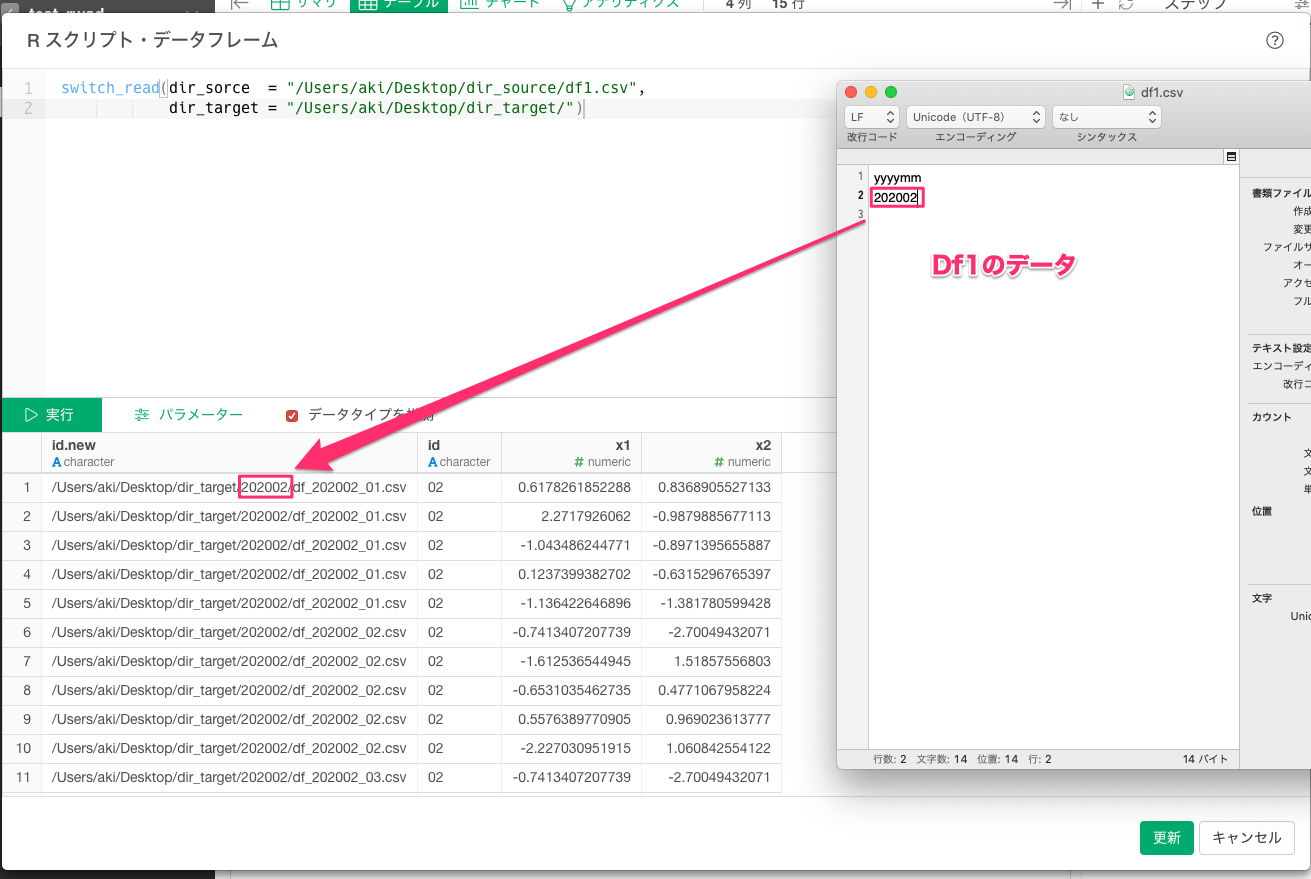
③時間が立ってdf1の年月が"202002"に更新されたとする。なのでExploratoryのステップのインポート時点のRスクリプト・データを開き、更新すると**/**/**/202002からフォルダをdf1の値に応じて切り替えてインポート。
Exploratoryのパラメタ機能については、私はあまり詳しくないので、パラメタの回答はできませんが、こんな感じでいかがでしょうか。
参考になれば幸いです。
「いいね!」 2
たいへん参考になります、もはや芸術的。。。。
function化したカスタムスクリプト内で変数(yyyymm)側のデータも解釈させちゃうってことですね!
データフレームとして取り込んだものから吸い上げられないかと思っていましたがExploratoryだとそのデータフレームオブジェクトの本名(rds?)がちょっとわかりにくいので困っていました。
が、これができるなら、と思ってどうにかrdsを見つけて
そこからご教示いただいた情報を元に
変数yyyymmを取り出してスクリプトを作ってみたところ、
期待した動作を実現できました。
ありがとうございます!
「いいね!」 1
@Yasuhiro_Yatsuu さん
上手くいったようでよかったです!
少し工夫すれば、「Rでできることは、Exploratoryからでもできること」のはずなので、カスタムスクリプトを 使えばいろんなことできると思います!(私もまだまだですが・・・)
また、お困りごとありましたら、お気軽にどうぞ~。
「いいね!」 1
@Yasuhiro_Yatsuu さん
Exploratoryのパラメタ機能で検証してみました。
結論からいうと、似たようなことはできました。前回の方法では、df_sourceのデータが更新されることで、"202001"や"202002"という文字列を取得していましたが、パラメタを使えば、そこのデータ自体がいらず、Exploratory上で"202001"や"202002"とパラメタに値を入力すれば、読み込むフォルダを変更できます。
①データを読み込む際には R スクリプト・データフレームで下記を実行。
tag <- @{yyyymm}
## フォルダへのパスは良しなに変更ください
path <- stringr::str_c("/Users/aki/Desktop/dir_target/", tag)
dir_csv <- list.files(path = path, full.names = TRUE, pattern = "*.csv")
df <- sapply(X = dir_csv, FUN = readr::read_csv, simplify = FALSE) %>% dplyr::bind_rows(.id = "id")
df
②上のコードを保存する前に、パラメタを作成。デフォルト値を設定しないと、そもそもの読み込みができないので、デフォルト値を設定。
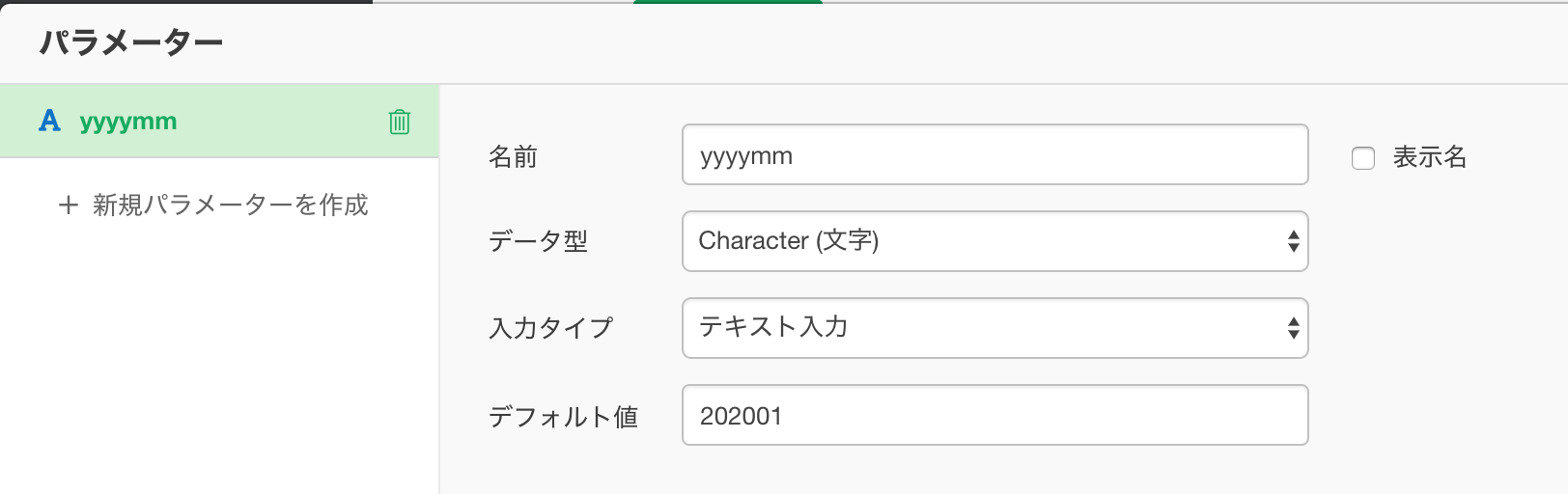
③保存すると、デフォルト値の202001のフォルダのcsvを読み込む
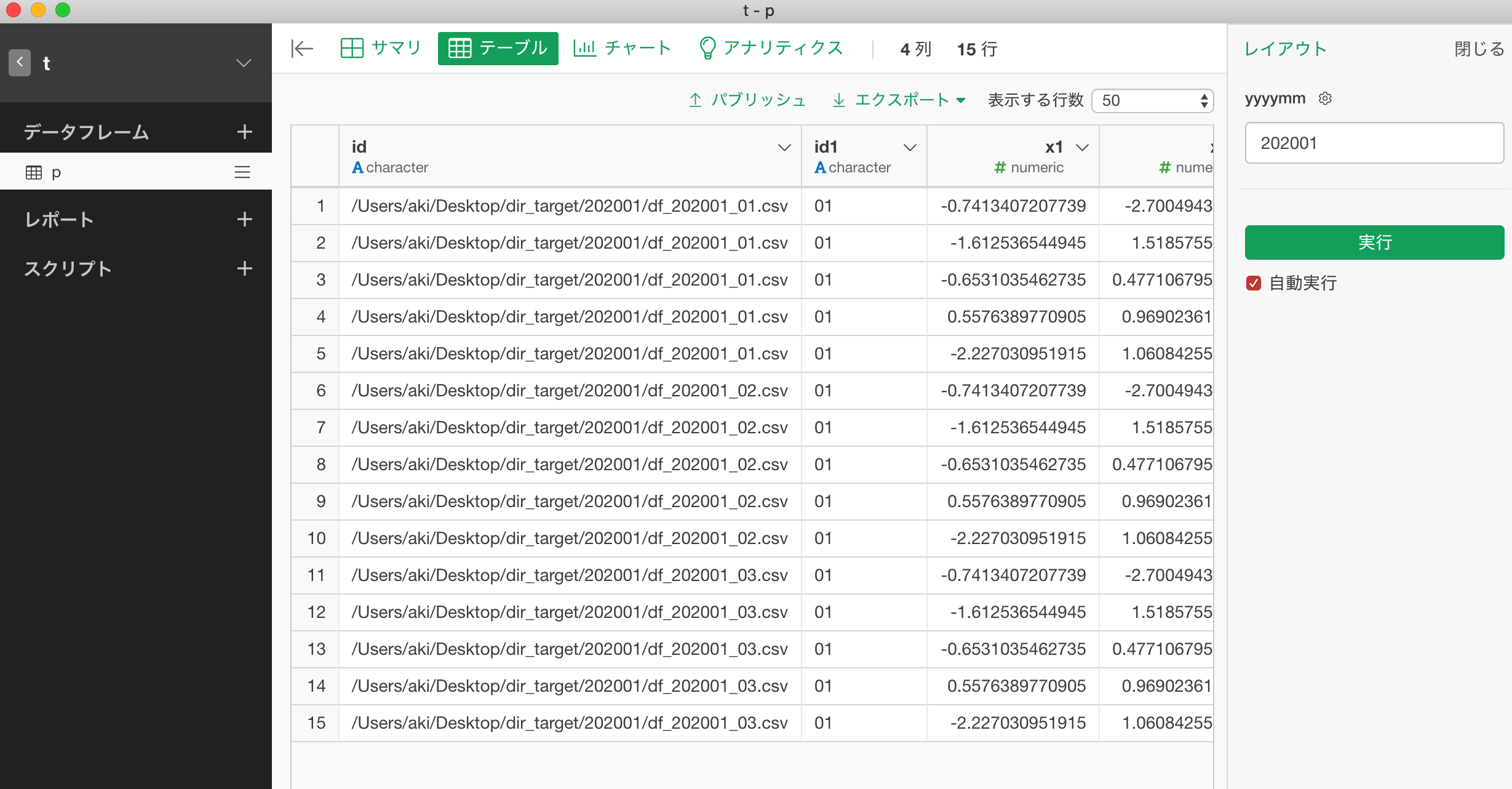
④フォルダの読み込み先を変更するタイミングでExploratory上でパラメタの値を変更。ここでは、202002フォルダに変更
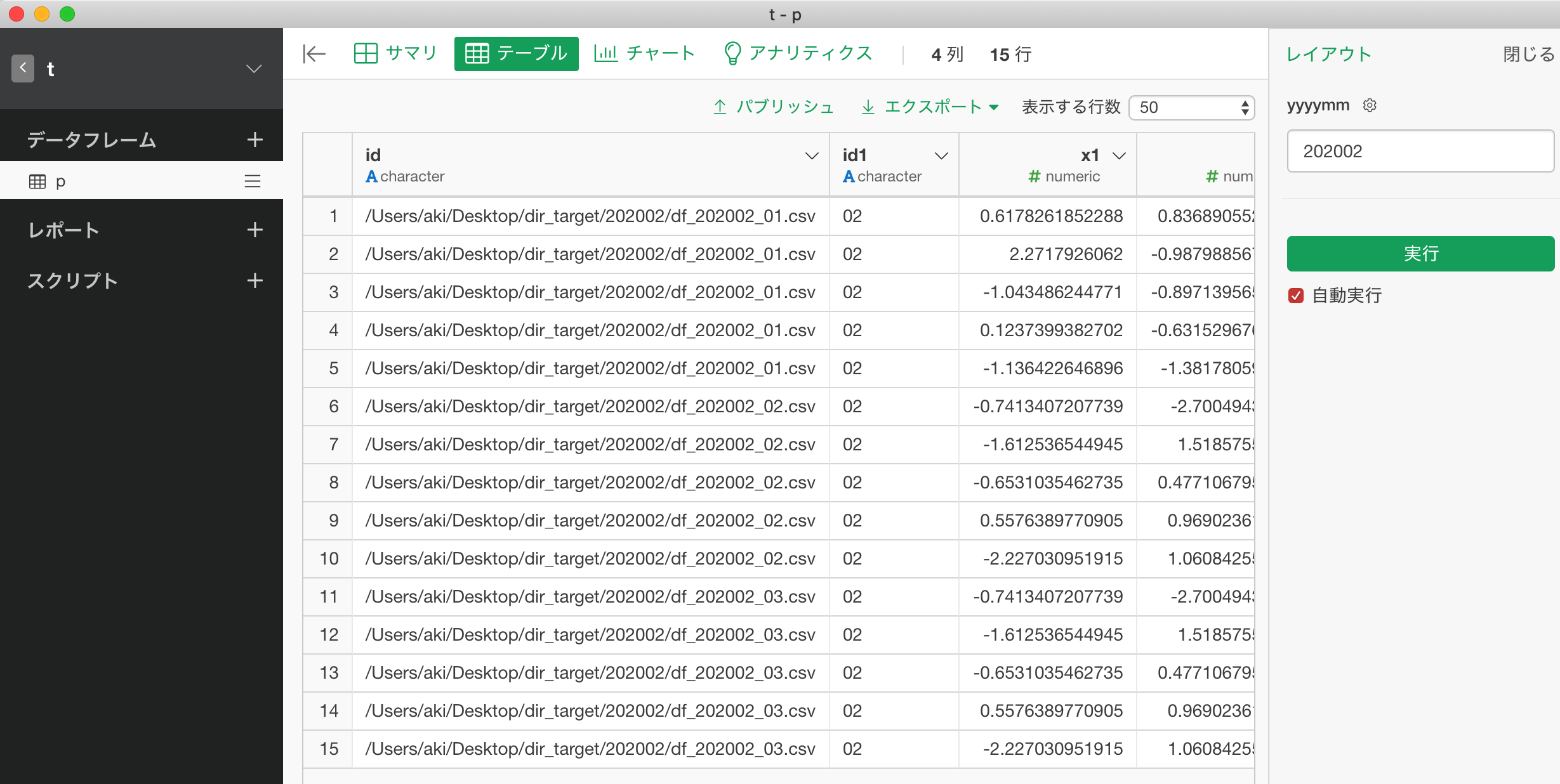
こんな感じです。参考になれば幸いです。
「いいね!」 2
重ね重ねありがとうございます。
パラメーターを使う場合、やはりパラメーター自体を手動で更新する手間が必要になると理解しており、またそのパラメーター機能自体がUI的に若干奥まったところにあるため、使うべきかどうかが悩みどころでした。
ただ、ご教示いただいた方法もたいへん刺激的です。
実際今回のケースですと、YYYYMMに(月の増減計算等も含み)関連したソースデータの
更新作業が3つほどあるので、この方法でそれぞれパラメータを参照させれば、
「参照されている全てのソースデータを再インポート」で一気に3つのソースデータを更新できるかもしれません。
そうなれば、
データソースを決められた順番通りに3回再インポートする操作
vs
パラメータの手動更新+「参照されている全てのソースデータを再インポート」を1クリック
だと後者のほうがオペレーションが楽になるので、
やってみる価値はありそうですね!
「いいね!」 2
やってみました。
予想していなかった効果として、たしかにパラメータそのものは手動で更新する必要があるのですが、その時その変化を反映させるために「実行」する必要があり、
(私の個人的な状況だけかもしれませんが、データがそれぞれ大きいので「自動実行」はオフにしました)
なんとそれによって各データフレームも自動的に再インポートされ、
想像以上の工数削減が実現できました!
気づきをいただき本当にありがとうございました!
P.S.
一番ハマったのはロジックそのものよりもファイルパスを加工する際の文字コードの扱いでした。。。
# パラメータは@{yyyymm}とする
library(dplyr)
library(readxl)
library(stringi)
input_path <- "c:/データ/"
file_name <- "/ほげほげ.xlsx"
file_path <- stringi::stri_conv(str_c(input_path,@{yyyymm},file_name))
# ↑これをしないとEvaluation error: zip file ~~cannot be opened.になってしまう
readxl::read_excel( file_path, col_names = TRUE,col_types="text")
「いいね!」 2