(本文)XXXXXXXXXXX。(概要)
といった文章があり、XXXXXXXXXXX。を取り出したい場合、
一旦、(本文)を "", (概要)を"@“にstr_replaceを用いて、それぞれ置換し、str_extract_insideで”“と”@"を抽出するのが良いのでしょうか?
それとも、直接的に、(本文)と(概要)を指定し、その間を抽出する方法はあるのでしょうか?
高橋
(本文)XXXXXXXXXXX。(概要)
といった文章があり、XXXXXXXXXXX。を取り出したい場合、
一旦、(本文)を "", (概要)を"@“にstr_replaceを用いて、それぞれ置換し、str_extract_insideで”“と”@"を抽出するのが良いのでしょうか?
それとも、直接的に、(本文)と(概要)を指定し、その間を抽出する方法はあるのでしょうか?
高橋
「(本文)XXXXXXXXXXX。(概要)」という文字列について、
本文に該当する部分を省略するために「(本文)」と表記しているのか、
本当に「(本文)」という文字列があるのかわかりませんが、
後者を想定して回答いたします。
※前者の場合、文字列の検索に関する質問で具体的に文字のパターンがわからないと回答しにくいためです。
下記のように正規表現を使うのはいかがでしょうか。
もしかすると、もっと良い正規表現があるかもしれませんが、
ぱっと思いついたのが下記でした。
# ここでの括弧は半角を想定しています。
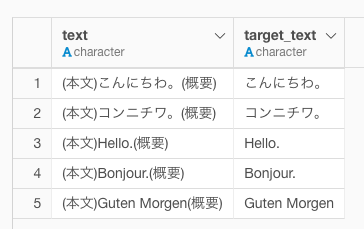
stringr::str_extract(string = text, pattern = "(?<=\\(本文\\)).*(?=\\(概要\\))")
textがもとの文字列で、target_textが抽出後の文字列です。
なにかのご参考になれば幸いです。
わさびさん
(本文)、(概要)という文字列が実際にある文字列ですので、わさびさんの想定は合っています。
正規表現は使い慣れないので、考えつかなかったです。ありがとうございます。
色々と検索しつつ、下記のサイトに行き着き、それぞれの正規表現の意味が分かりました。
https://userweb.mnet.ne.jp/nakama/
https://www.megasoft.co.jp/mifes/seiki/meta.html#replace
いつもありがとうございます!
