Exploratryのランダムフォレスト>変数重要度の結果を人に見て頂いたところ、変数重要度は項目ごとにまとめて出せないのではないか?との質問を頂きました。
変数重要度は「予測変数の項目ごと」に結果が出ますが、本来「予測変数項目」×「意」ごとに結果が出るのでは?という問いです。
もちろん現状が見易いと思っているのですが、、
質問
①こちらは予測変数の項目ごとの1意の値を足し合わせて、予測変数の項目のimportanceを決めているのでしょうか??
②予測変数項目×1意の値ごとの変数重要度も作れるのでしょうか??(というか、それが予測影響度なのでしょうか??)
③これは別の質問なのですが、現状の変数重要度の結果を数値でも出せたりするのでしょうか??例えば店舗の成績データで店舗ごとのランダムフォレストをしたとして、その変数重要度ごとにクラスタ分析など出来たりするものかと思いまして、、
- こちらは、ある予測変数があったときとなかったときでどれだけ予測精度が変わるかというのを計算するための、Purmutationというロジックを使って出しています。
- この場合は、One-hot-encodingというステップを使ってカテゴリーのそれぞれの値を列にして、それらを予測変数として含めてからランダムフォレストを流せばできます。
- 右上のエクスポートボタンよりデータをエクスポート、または新しいデータフレームを作ることができます。
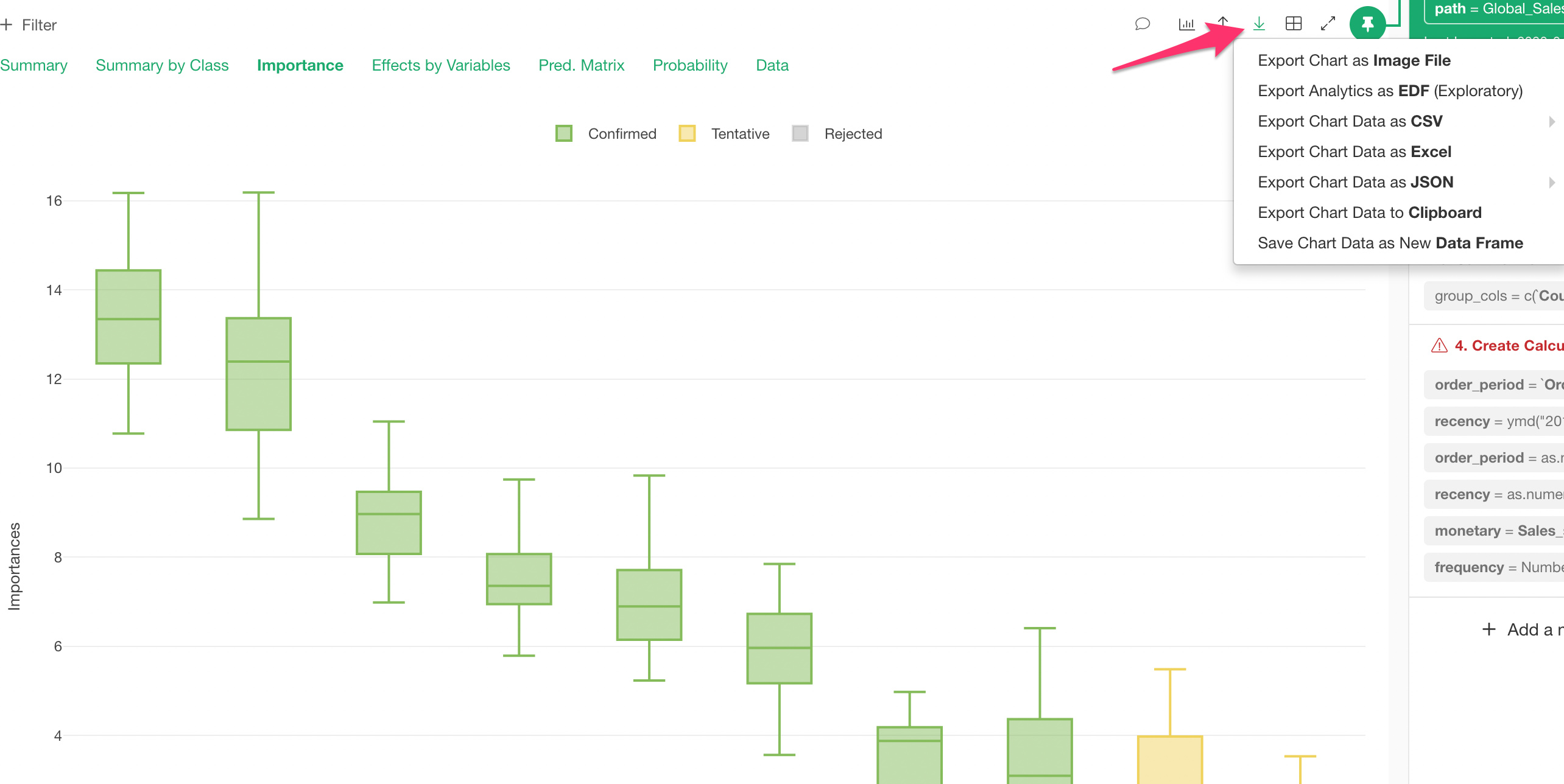
ランダムフォレストの1つの利点として、カテゴリー型の変数をOne-hot-encodingして列に変換しなくても良いというのがあります。そのせいで、そのままカテゴリー型の変数の重要度を計算することができます。
例えば、線形回帰などの統計タイプのモデルだとそうはいきませんので、それぞれの値が変数となります。これはモデルを流すと勝手に変換の処理が行われます。
また機械学習でもXGBoostなどのように数値型の変数でないと取り扱えないようなものもあるので、その場合は事前にOne-hot-encodingを行う必要があります。
他にも質問などございましたら、お気軽に!
西田
ちなみに、One-hot-encodingはこちらからアクセスできます。
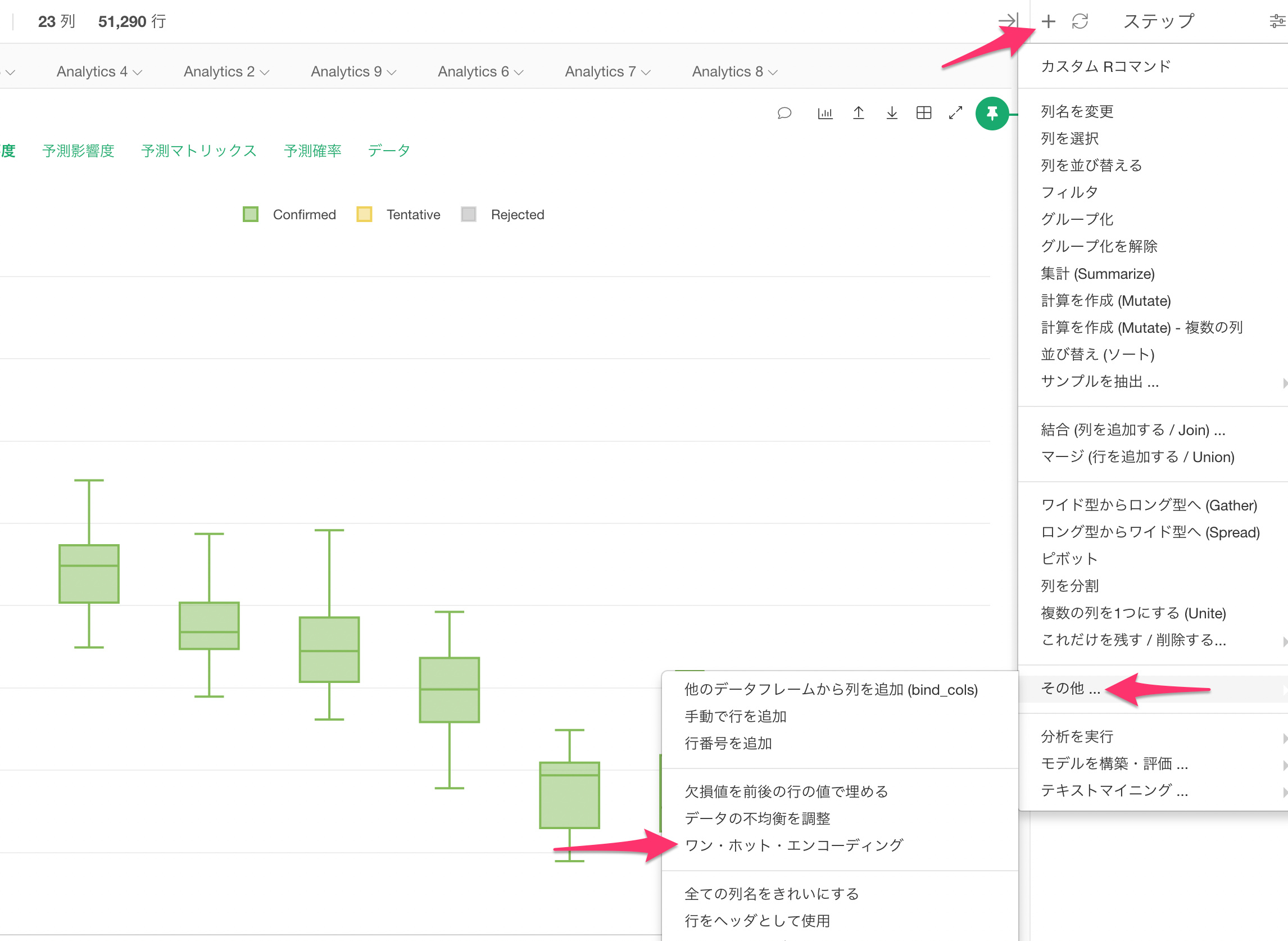
間が空いてしまいまして申し訳ありません。
ありがとうございました!
こちらワンホットエンコーディングを実行しようとすると以下のようなエラーが出るのですが解決策ありますでしょうか??
「トランスフォームステップが不完全か無効のようです。実行する前にトランスフォームステップを修正してください。」
こちらのワン・ホット・エンコーディングでのエラーですが、日本語のUIのときに出てしまうエラーのようです。
すでにこちらの問題は修正しており、次に出るバージョンで解決される予定です。
回避策としては、一度英語のUIに変更してからワン・ホット・エンコーディングを実行すると問題なく動きます。
@yoshio_ishimasu さん
横入り失礼します。
私の手元の環境でもエラーがでました・・・が、One-hot-EncodingはExploratoryの他の関数を組み合わせれば、実現可能ですので、ワークアラウンドとして、下記参考になれば幸いです。
すでに解決済みであれば、申し訳ありません・・・
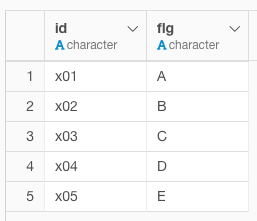
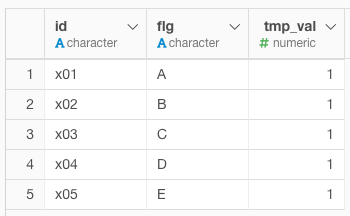
①加工前のサンプルデータ
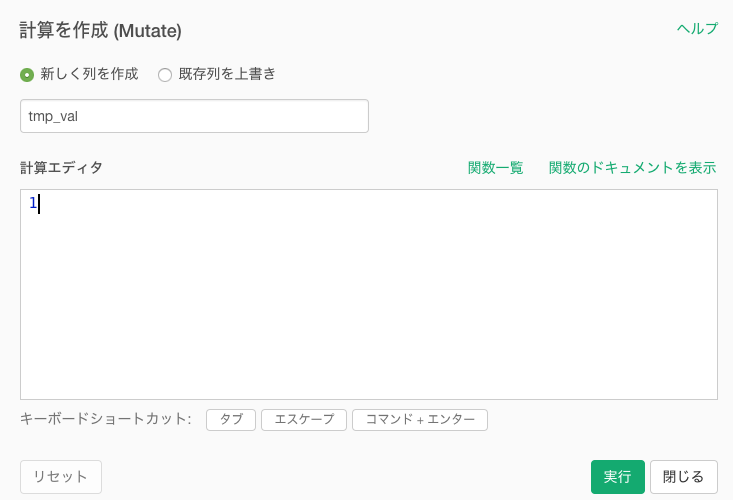
②集計用フラグを作成
後ほど使う集計用のフラグをつくります。ただの整数の1です。
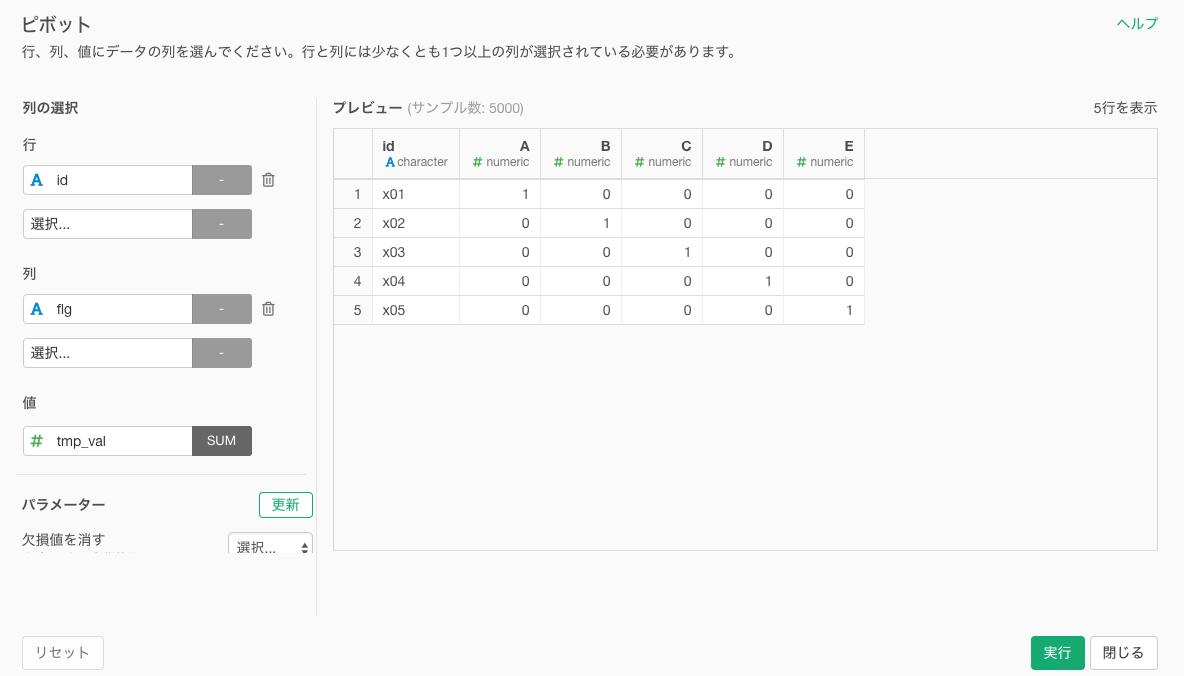
③ピボット関数
行;id
列:flg
値:tmp_val-SUM
※1ID1行のデータを想定しています。1ID複数行ある場合は、MINとかに変更してください。
パラメータ:初期値=0と設定します。
④加工後のデータ
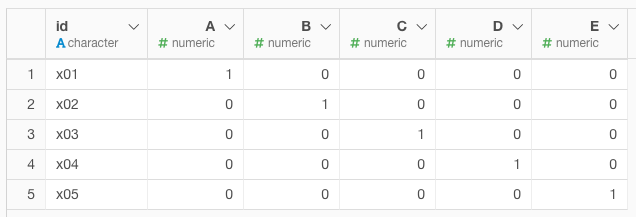
なにかの参考になれば幸いです。
ご不明点あればお気軽にご連絡ください。
よろしくお願いします。
==============
追記
どうやら日本語UIのときに出てしまうエラーのようで、英語のUIに変更すると実行できるようです。
「いいね!」 2
wasabiさん
ありがとうございます!!
なるほど、、わかりました。
ちょっと数日exploratoryが事情で使えないのですが、、
、、ぜひ試してみます!
取り急ぎアドバイスのお礼まで。
「いいね!」 2
wasabiさん、出来ました!ありがとうございます!
新たな集計列の作成やピポットも関数もですが、、
色々と他の関数の組み合わせで代替え策、回避策が出来るという点も
勉強になりました。
ありがとうございました!!
shirotoさん
ご確認ありがとうございます!承知しました!
「いいね!」 2