ランダムフォレストを実行しようと思っていますが、その前に欠損値を近傍法で埋めたいと思っております。
Exploratoryを用いて、欠損値を埋める方法はどのようにすれば良いのでしょうか?
XLSTATでは、処理の時点で欠損値を近傍法により埋めて処理をしてくれる機能がありました。
別の処理でも別のデータを処理するため、Exploratory上で欠損データの補正を行う方法を教えていただきたいです。
ちなみにデータは投稿論文として扱うため、平均値や前後の値で埋める方法は避けたいと思っています。
「いいね!」 1
ランダムフォレストを実行する前に欠損値を近傍法で埋めたいということであれば、
knn()でモデルを学習させて、欠損値のデータを使って予測するでも問題ないとおもいますが、
simputationというパッケージをインストールいただき、そのパッケージの関数impute_knn()で欠損値補完をしてしまうのが便利かと思います。詳細は下記のドキュメントを参照ください。
下記サンプルです。
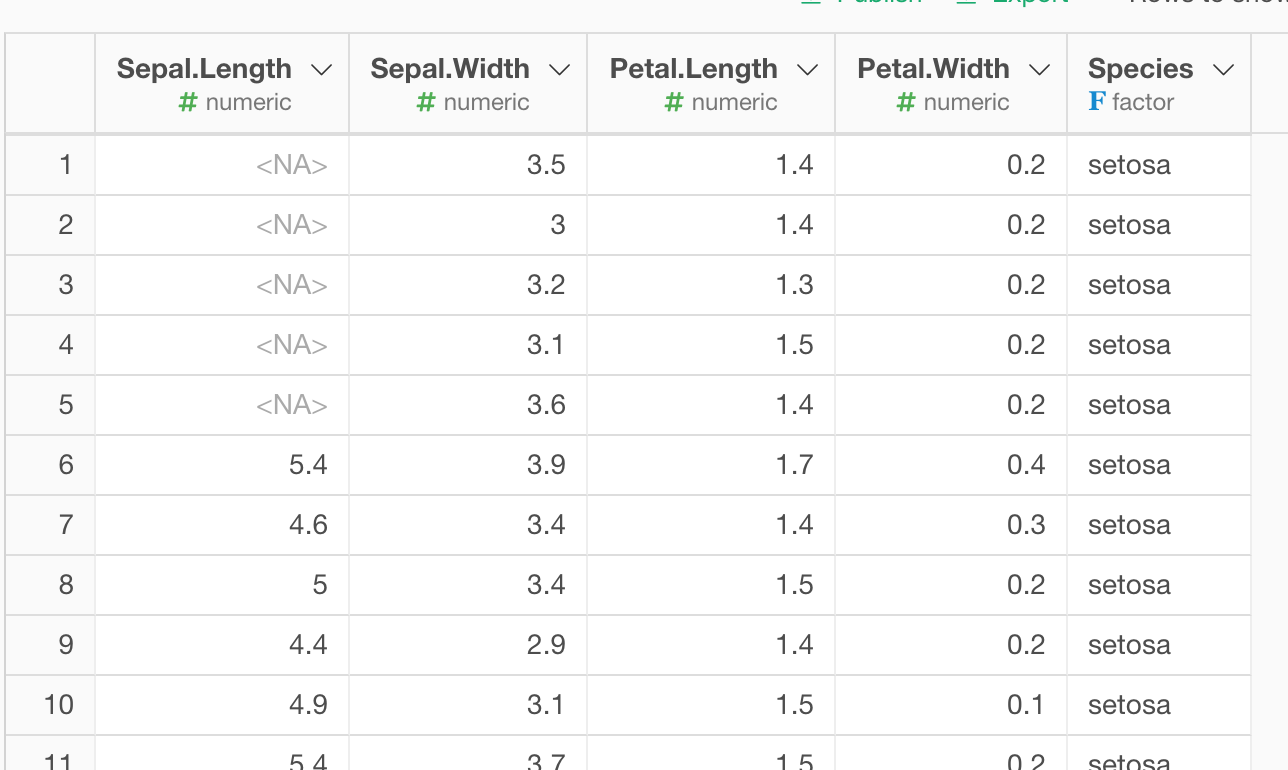
①欠損値のデータ
②カスタムスクリプトを記述します
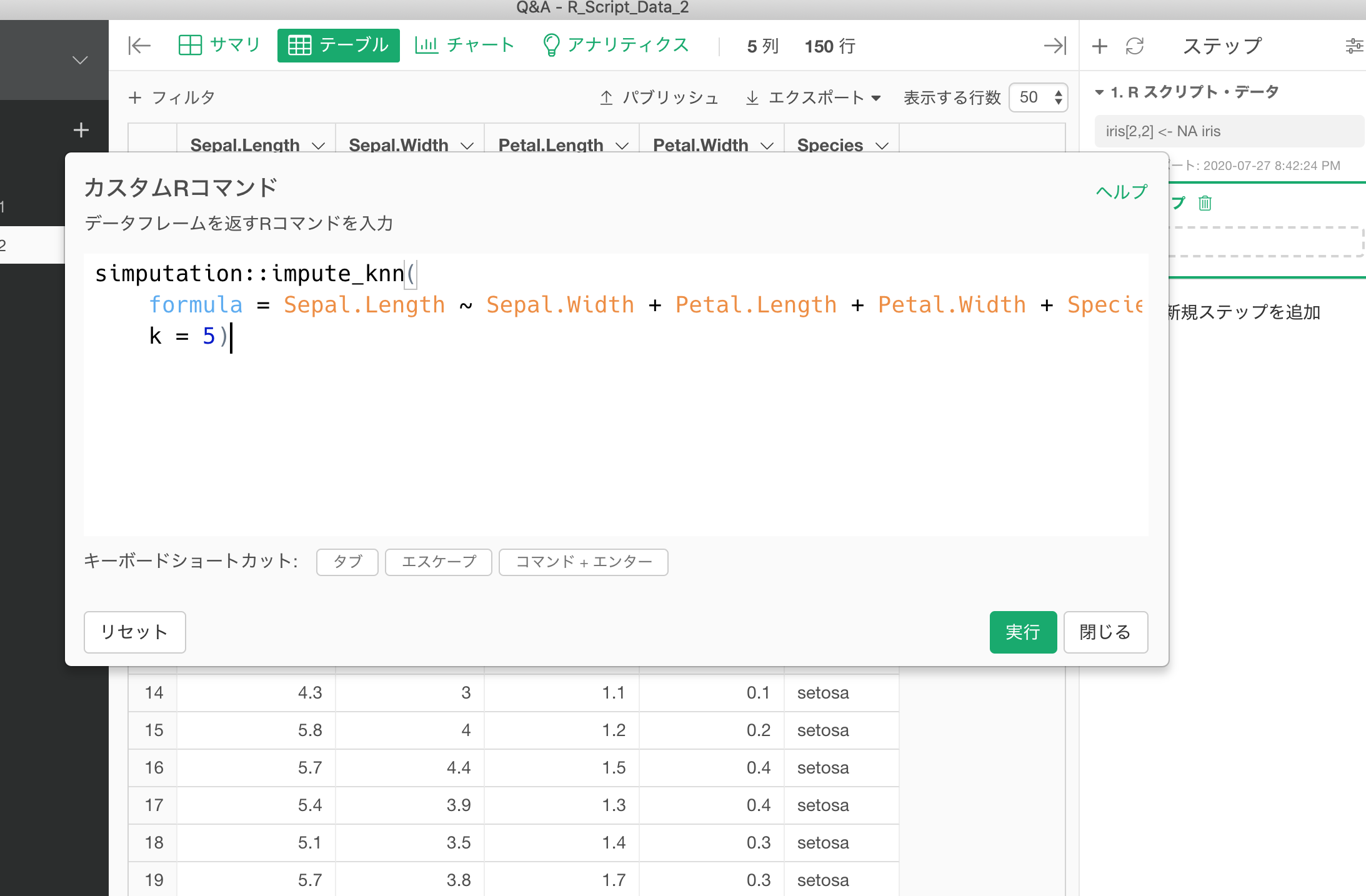
kNNのモデル式はデータと分析内容に応じて変更してください。
simputation::impute_knn(
formula = Sepal.Length ~ Sepal.Width + Petal.Length + Petal.Width + Species,
k = 5)
③欠損値が補完
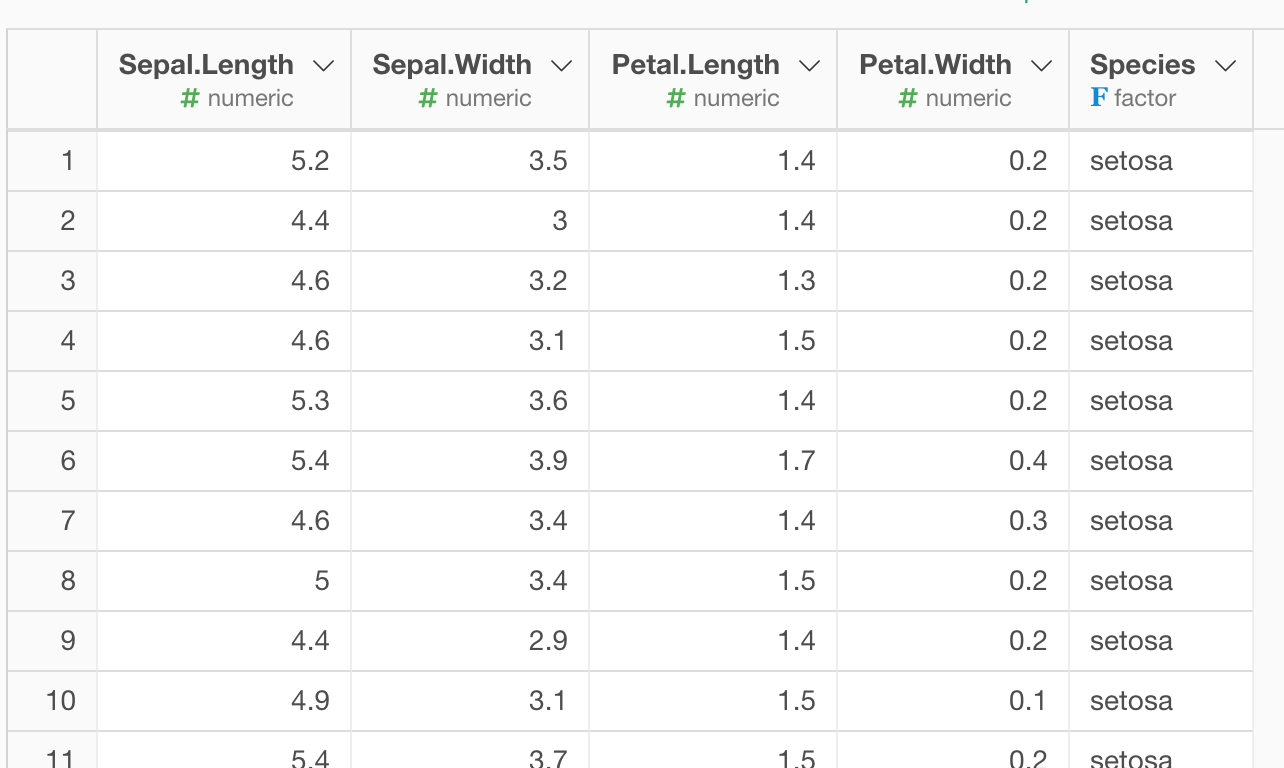
こんな感じでいかがでしょうか。
「いいね!」 2
返信できれおらず、すみません。ありがとうございます。
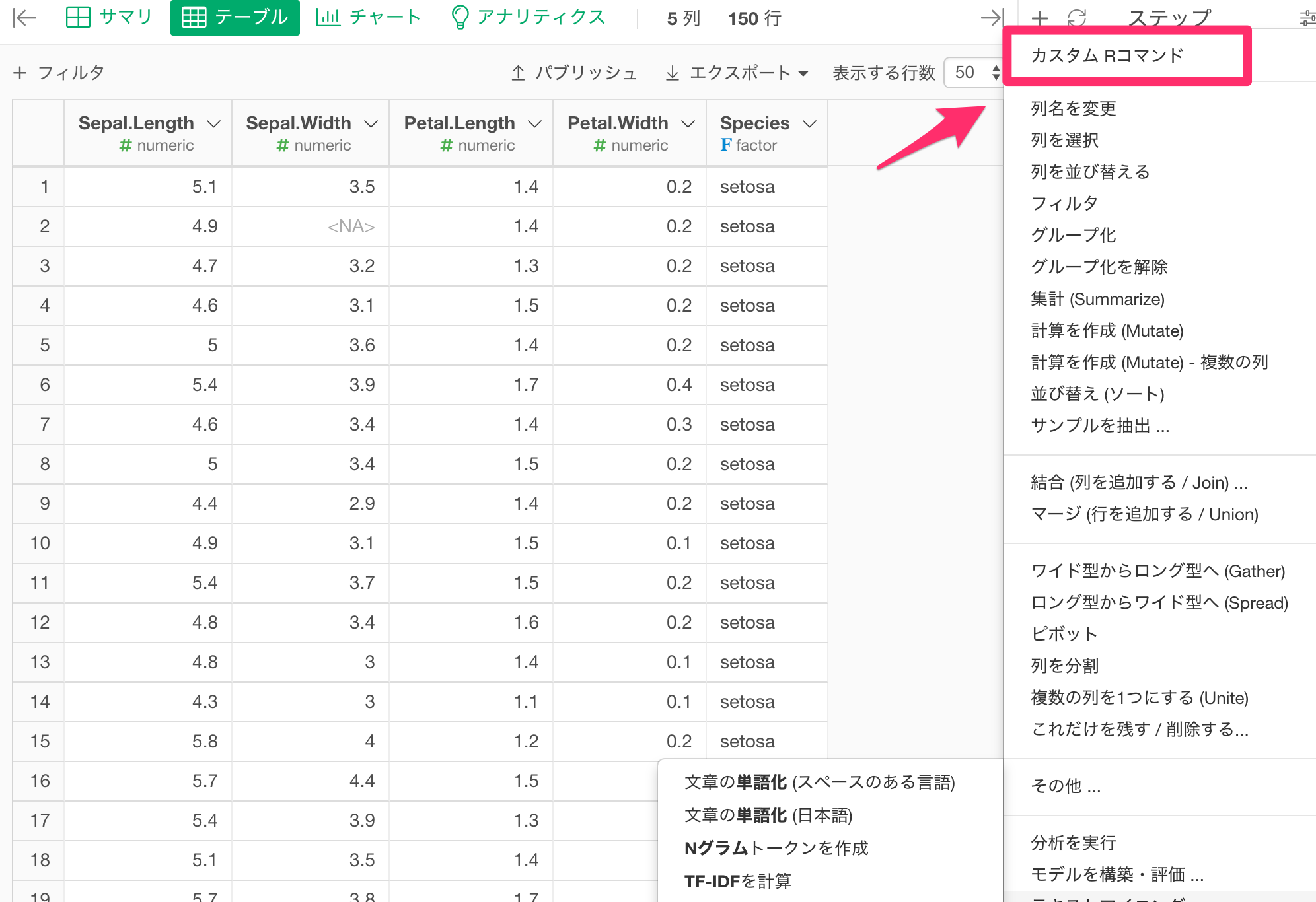
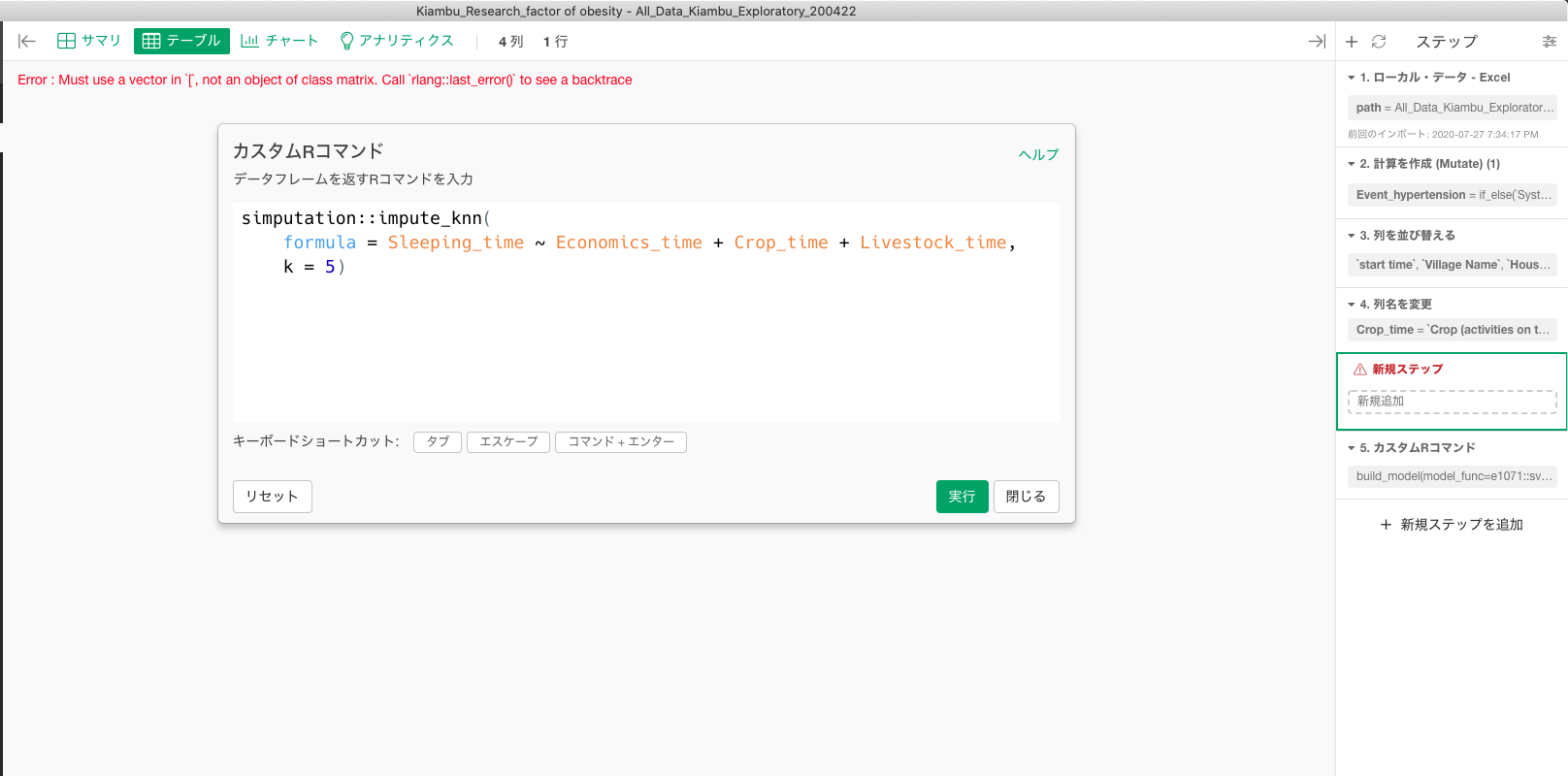
上記の実行に関しては、カスタムクリプトと記述してある部分に関しては、「カスタムRコマンド」のことを指しておりますか?いまいちソフトウェアの使い方がわかっておらず。。。。
いただいた方法で実行すると上記のようなエラーを吐き出します。。。。
どのように対処して良いかわからず教えていただけると幸いです。
@KENTA_HARA さん
このエラー文からでは、ちょっとわかりかねるので、可能であれば、1つ前のデータステップに戻って、「テーブル」タブから、どんなデータの欠損値を埋めようとしているのか、見せていただくことは可能でしょうか?エラーをこちらでも再現したいです。
見せること難しい場合は、下記のように、カラム名、データ型、ダミーの値を教えていただけると幸いです。
Sleeping_time : numeric : 10
Economics_time : numeric : 5
・・・
欠損値を埋める対象のデータセットが4列1行というサイズも気になりますが、4列1行のデータの欠損値を埋める予定なのでしょうか?
お手数をおかけしますが、よろしくおねがいします。
データセットに関しては記載の通りです。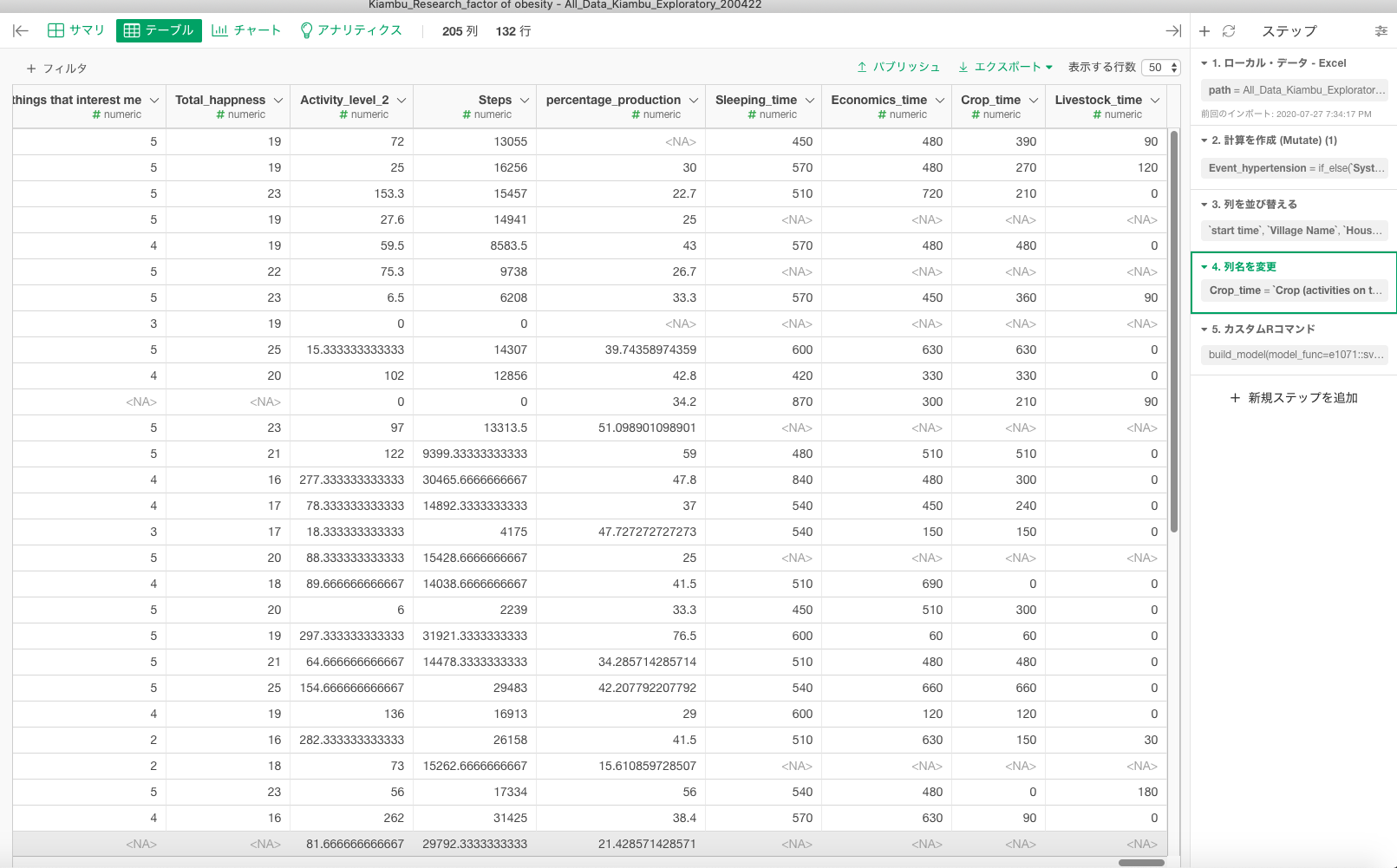
@KENTA_HARA さん
ありがとうございます。
似たようなデータセットを作り、エラーを再現できました。
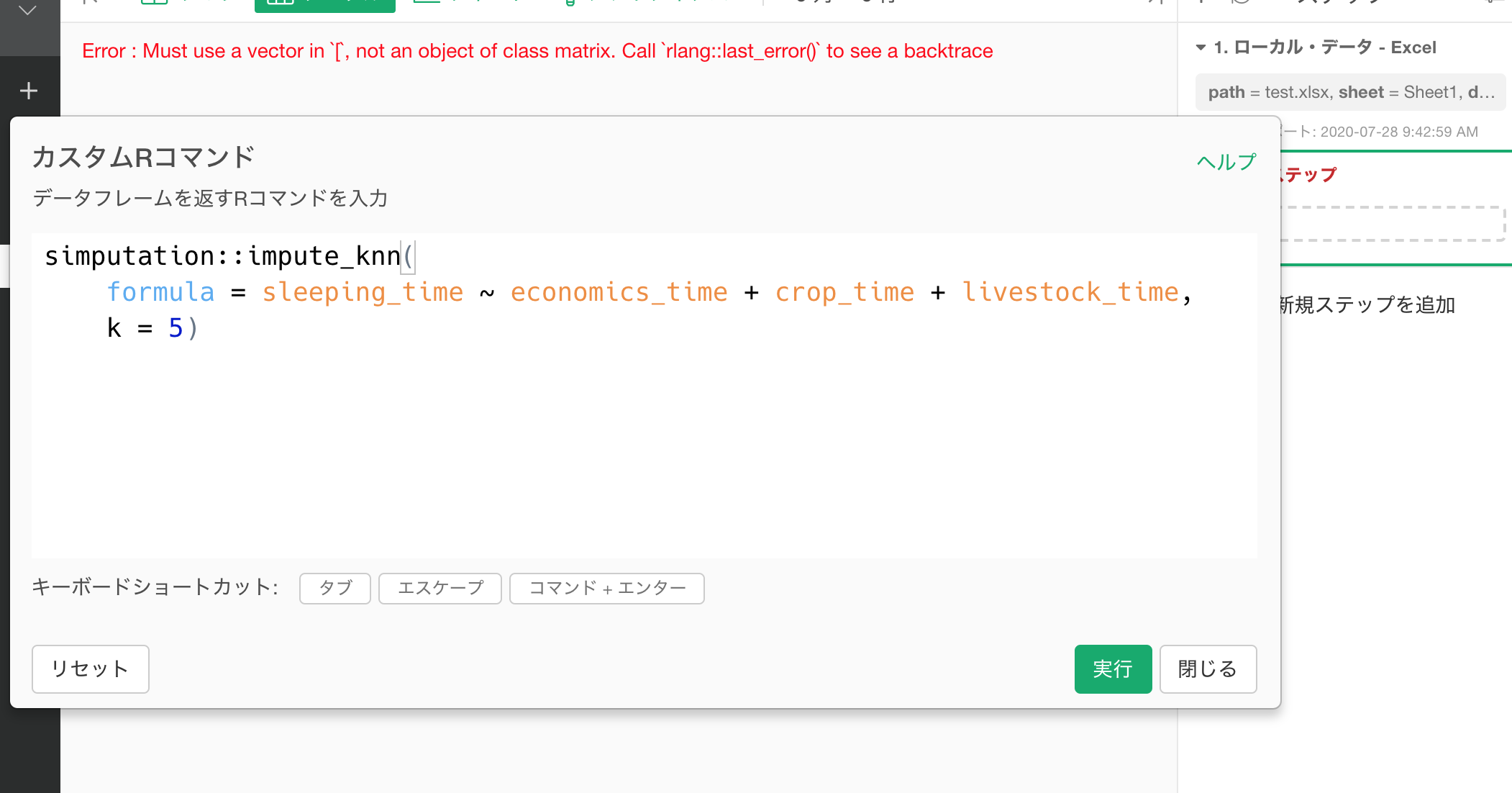
エラー回避のワークアラウンドとしては下記の通り実行すれば、エラーは起こらないかと思います。
as.matrix() %>%
simputation::impute_knn(
formula = sleeping_time ~ economics_time + crop_time + livestock_time,
k = 5) %>%
as.data.frame()
なのですが、1点気になった部分があります。見せていただいたデータセットの例えば、4行目の説明変数(特徴量)はすべてNAですし、6,8行目もすべてNAかと思います。他にも同じような行が多くあります。
k近傍法では下記のように指定することは、
sleeping_time ~ economics_time + crop_time + livestock_time
economics_time、crop_time、livestock_timeの値をもとに近傍の点からsleeping_timeの値を推測することになるため、economics_time、crop_time、livestock_timeがNAだと、ワークアラウンドしてエラーを回避したとしても、sleeping_timeの欠損値は補完されずNAのままかと思います。
impute_knn ()の関数の中身を細かく見ていないので、正確かどうかはわかりませんが、上記のような状態であるため、エラーが発生したものかと思われます。
よろしくおねがいします。