こちらはユーザー様よりご質問いただいたものを、他の方にも参考になるかと思いデータを変えて紹介しております。
※ データを変えているため、説明とスクリーンショットがあっていない部分があります。
Q1: push通知のon/offを目的変数とした時に、どの説明変数が影響を与えるのかを見ようとしています。登録日に特徴が見られると考えているのですが、1995年以降にoffにする割合が高くなっていると解釈できるのでしょうか?
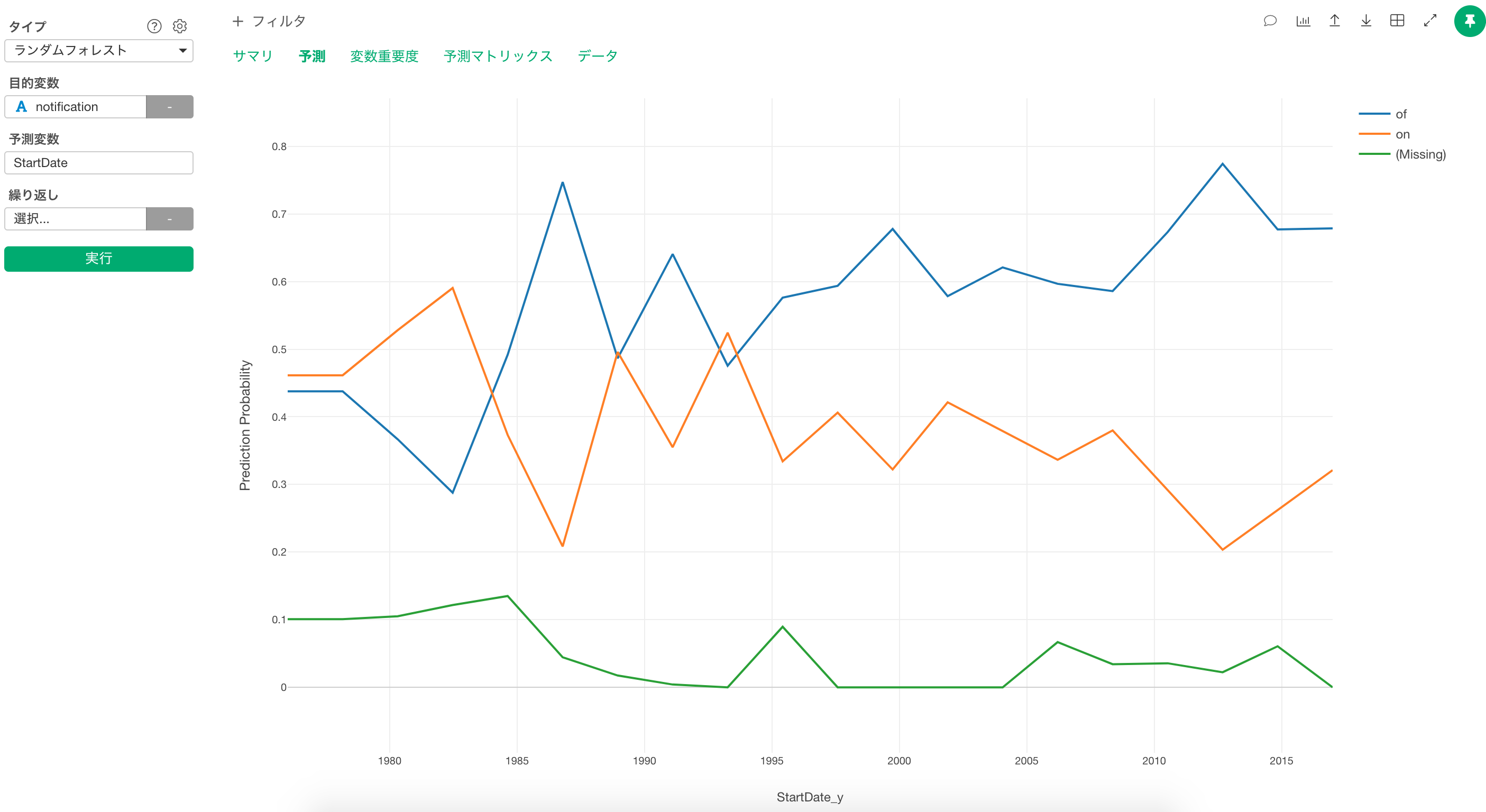
目的変数のデータタイプがCharacter型となっているので、予測影響度の値は、あるX軸の地点におけるプッシュ通知onの割合、プッシュ通知offの割合、欠損値の割合が出ております。例えば、2000年の場合は、onが6割、offが3割、欠損値が1割と全体で100%になるようになっています。
よくされるやり方としては、Character型ではなく、2値のロジカル型に変換してランダムフォレストなどを実行したりします。
これにより実測値と予測値を表示でき、実測値には信頼区間も表示されます。
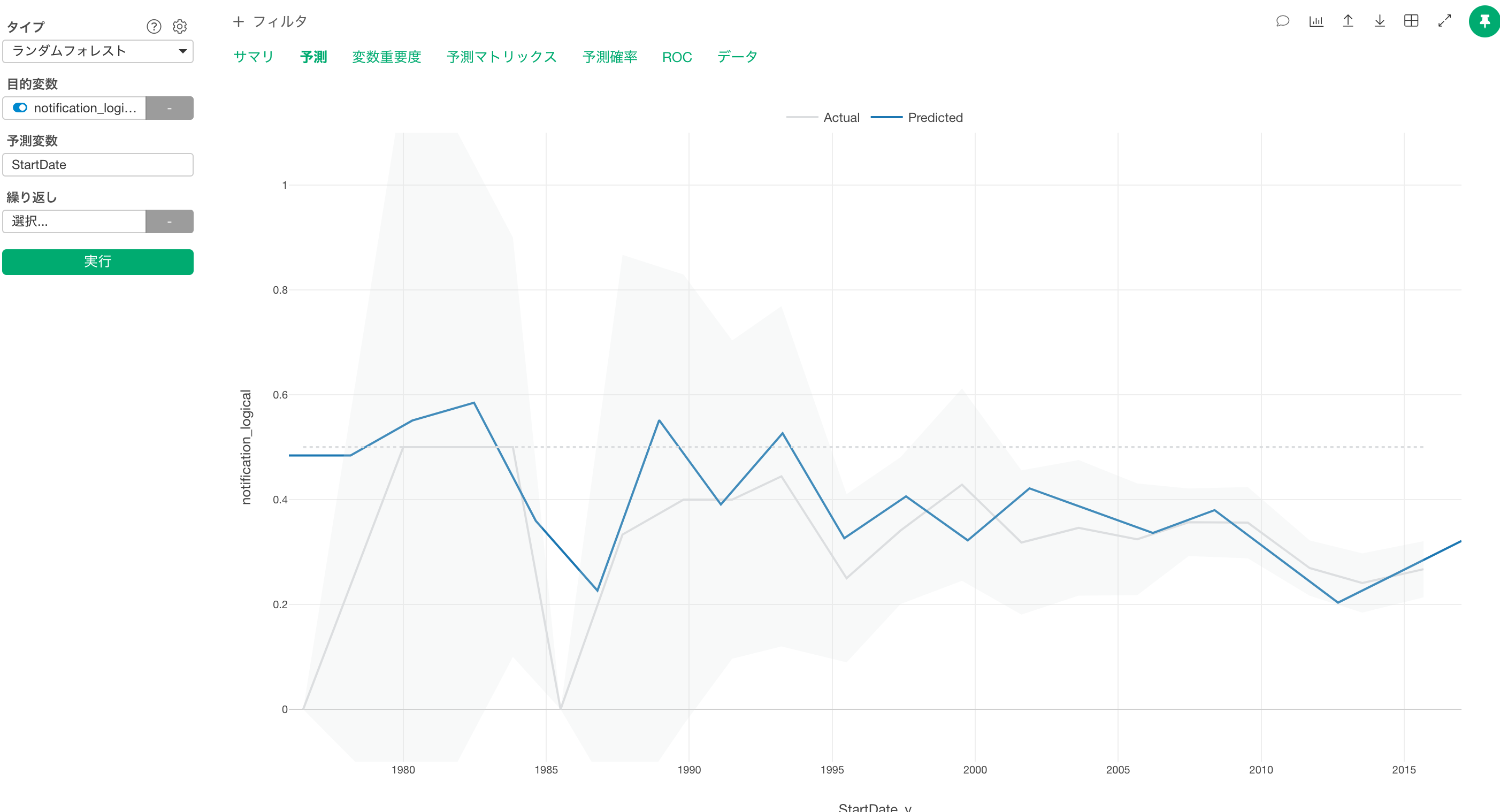
ロジカル型列の作り方は、計算を作成からnotification == "on"とすることでできます。
Q2: 信頼区間の幅が広いところに関してはデータがばらついているということでしょうか?
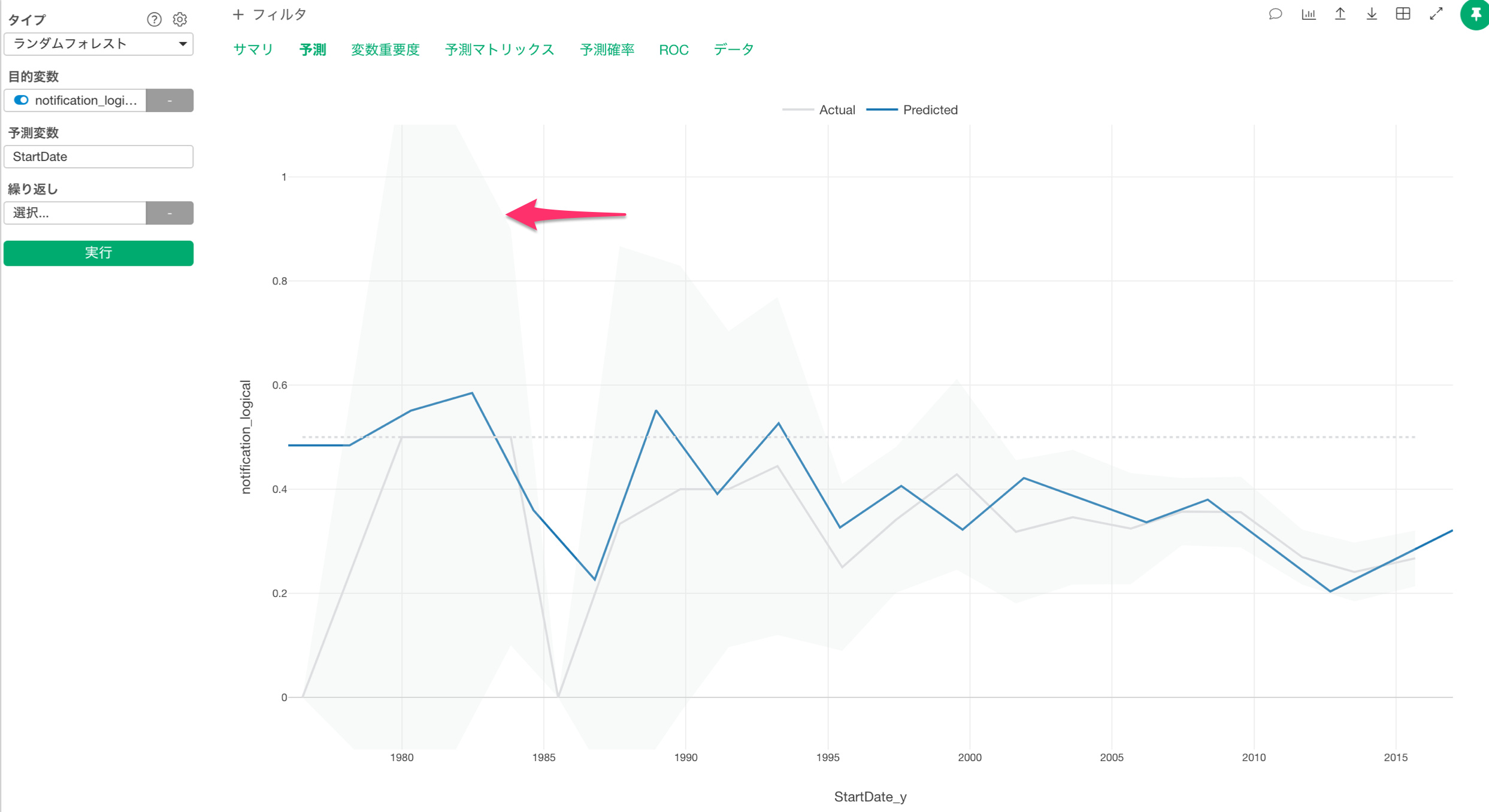
信頼区間の幅が広いということは、データがばらついていることもありますが、多くの場合データの数が少ない事が原因かと思われます。
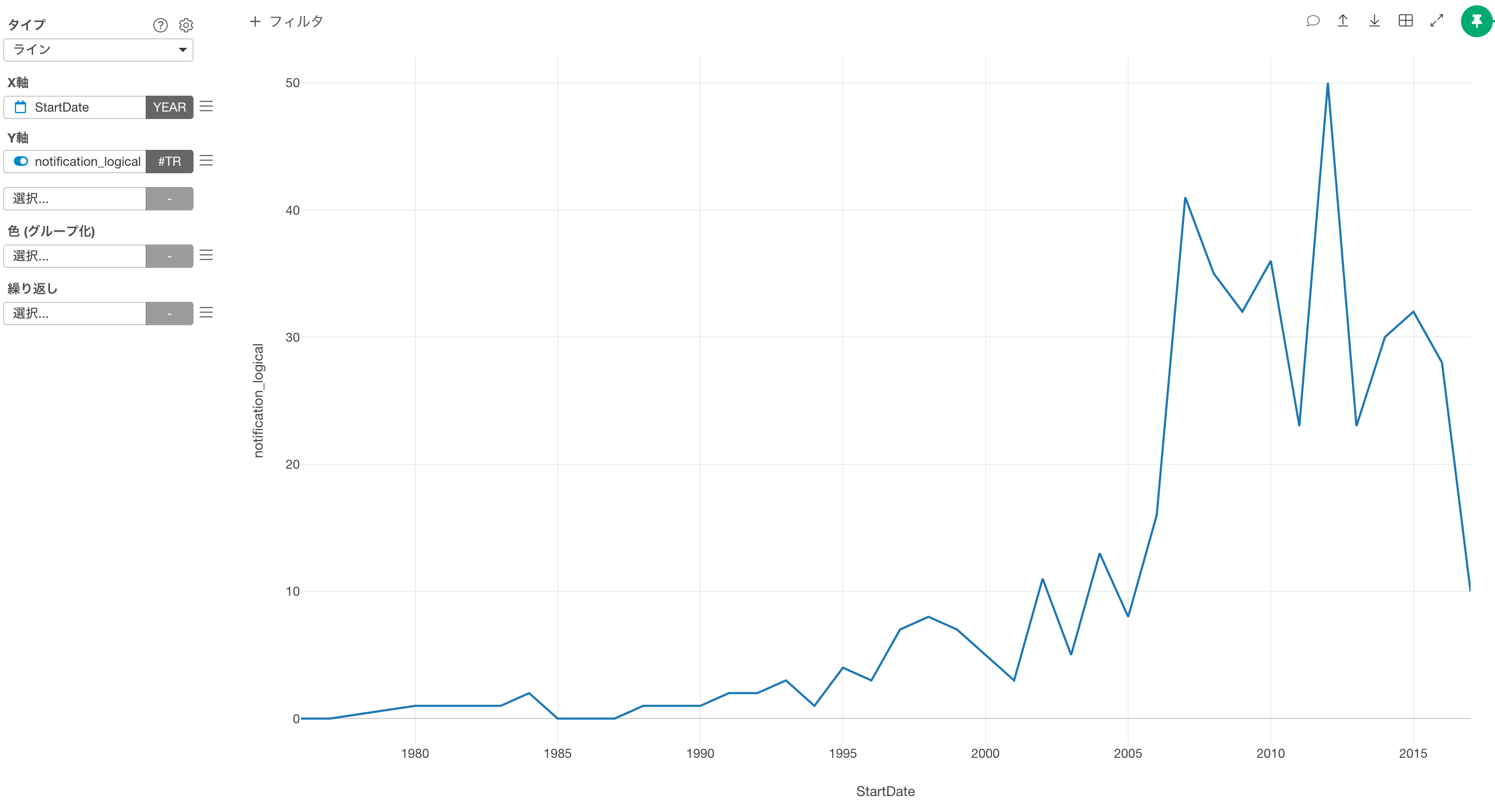
ラインチャートなどでデータの数を確認してみるといいかもしれません。
Q3: 予測タブのチャートにマウスオーバーすると、登録日の値に小数点が入っているのですが、1年ごとに正確に区切って見ることはできないのでしょうか?
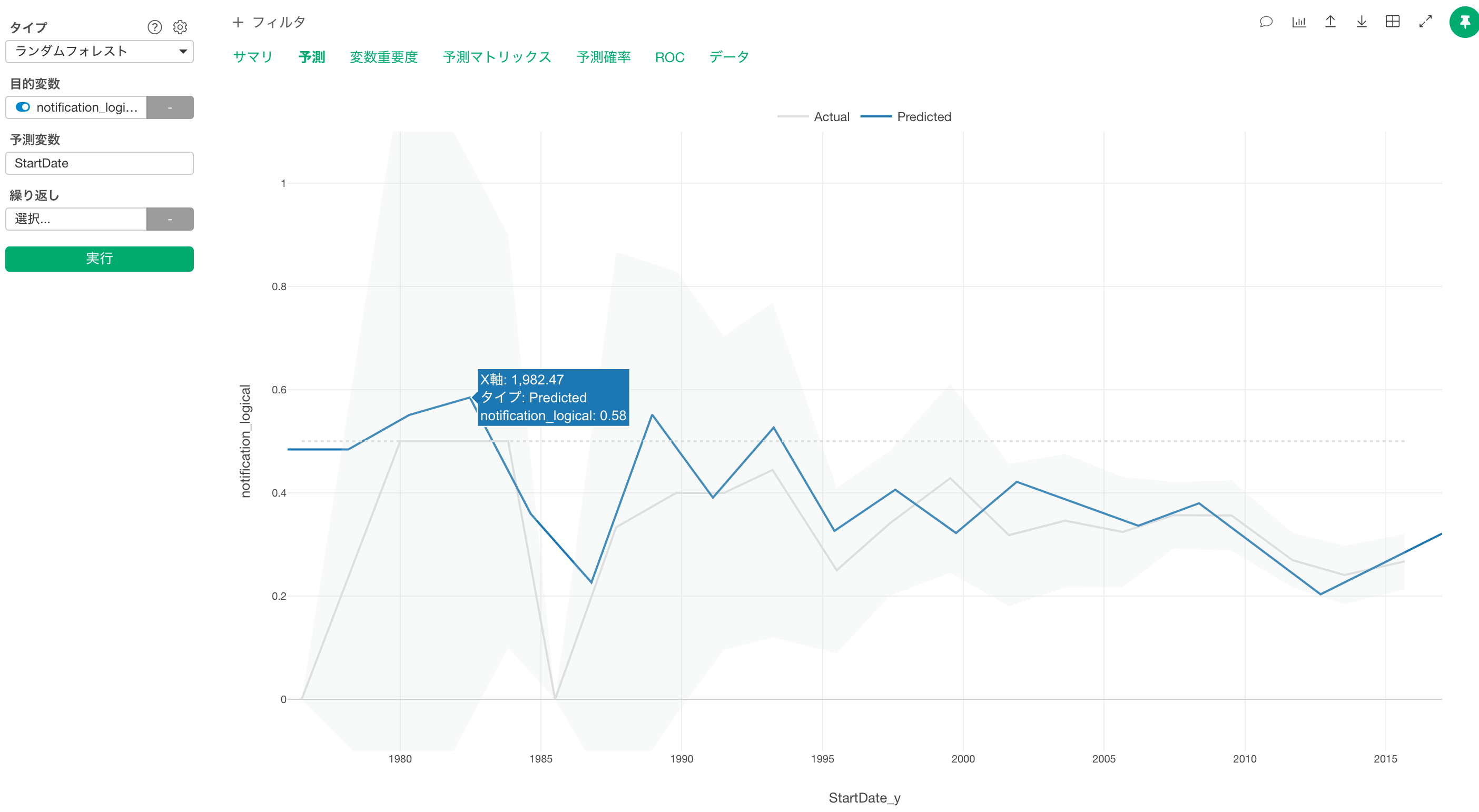
予測タブで描かれるチャートでは、裏で自動で区切り値を指定しているため小数点が含まれております。
1年ごとに区切ると言った機能は現状ないため、もし1年ごとに正確に見たい場合は、データタブからエクスポートをして、ラインチャートなどを作る方法があります。