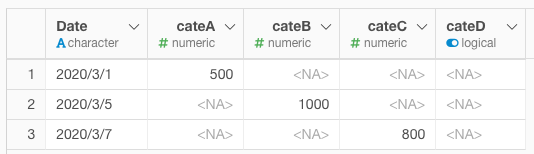
例えば、月次の商品売上明細があるとします。
3月が
商品カテゴリ 売上日 売上金額
-
カテゴリA 3月1日 500円
-
カテゴリB 3月5日 1000円
-
カテゴリC 3月7日 800円
-
カテゴリD 3月8日 1210円
というようなイメージです。
これを、商品カテゴリをキー列としたワイド型に変換して、
後工程に回すステップがあります。
後工程では
売上総額 = カテゴリA + カテゴリB + カテゴリC + カテゴリD
というようにそれぞれのカテゴリの列の売上金額を足し上げて、
売上総額の列を計算しているとします。
ところが、カテゴリDの商品は、他の商品と異なり内税表記になっているなどで、
そのカテゴリだけに適用する計算を行う必要があります。
これだけなら、例えば
カテゴリD = カテゴリD / 1.1
などの割戻し計算を作ってやればよいのですが、
ややこしいことに、カテゴリDは売れ線ではないので
月によりレコードが存在しない場合があります。
このような場合に、
エラーが出るたびにステップを修正するのは精神衛生上よろしくないので、
カテゴリDが存在すればその値を元に計算し、
存在しなければ新規にカテゴリDを作る(後工程に列として渡すため)というようなことをしたいです。
やり方としては、
-
データ読込時にRスクリプトで強制的に追加しておく
-
前工程のステップでそのデータ行が存在するかどうかチェックをかけて追加する
-
後工程のステップで列が存在するかどうかチェックを掛けて追加する
などが考えられると思っておりますが、いずれもうまく動かすに至りません。
なにかよい方法はないでしょうか。
@Yasuhiro_Yatsuu さま
「 1. 前工程のステップでそのデータ行が存在するかどうかチェックをかけて追加する」方法ですが、
下記のような関数はいかがでしょうか?
※ご存知かもしれませんがrlang::**とか!!の部分はTidy evaluationと呼ばれるもので、Rの作法なので、そんなものがあるんだ程度に流してください。
このinsert_if()はcheck_colで指定してカラムに、check_valueで指定した値があれば、そのままデータを返して、そうでなければ、check_valueで指定した値をcheck_colで指定してカラムにインサートする関数です。
insert_if <- function(data, check_col, check_value) {
# if you need input validation
col_en <- rlang::enquo(check_col)
is_category <- data %>%
dplyr::distinct(!!col_en) %>%
dplyr::filter(!!col_en == check_value) %>%
dplyr::pull()
if (!rlang::is_empty(is_category)) {
res <- data
} else {
res <- tibble::add_row(data, !!col_en := check_value)
}
return(res)
}
このようなデータがあった場合に、CateにはcateDがありません。
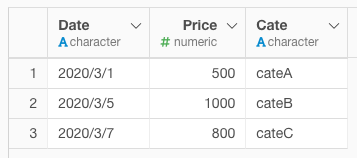
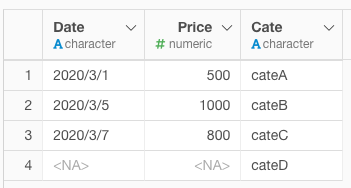
カスタムスクリプトで下記のように実行すると、CateにはcateDがないので、1行インサートされます。CateにcateDがある場合は、何もなかったようにそのままデータが返ります。
insert_if(data = ., check_col = Cate, check_value = "cateD")
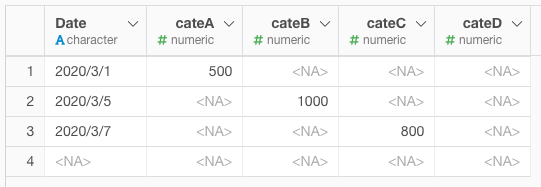
あとはWide型に変換し、割戻の計算を行います。値がないものをwideにするので、
NA行ができます・・・そこらへんはfilter()で処理するなど頂いければと思います。
※NAが0のほうが良い場合はspread(fill = 0)と設定ください。
なんだかあまり納得のいかない関数しか書けなかったので、少し考えていのですが…
「後工程のステップで列が存在するかどうかチェックを掛けて追加する」でも関数を作れたので、
お伝えします。こっちのほうが処理がへりますし良いかもしれません。
bind_if <- function(data, check_col) {
is_categroy <- any(names(data) %in% check_col)
if (is_categroy == TRUE) {
res <- data
} else {
tmp <- tibble(check_col = NA)
names(tmp) <- check_col
res <- cbind(data, tmp)
}
return(res)
}
Wideにしたデータに対して、
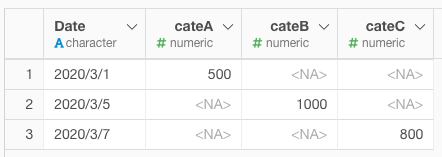
下記のカスタムスクリプトを実行。
bind_if(data = ., check_col = "cateD")
「いいね!」 1
こ、これは(^^;;;;;
めっちゃ勉強せなあきませんね(^^;;;;;;
まず私の理解があっているかどうか確認させてください。
前段でご提案いただいた方法は、
insert_if(data = ., check_col = Cate, check_value = “cateD”)
をステップにRコマンドとして追加し、
あらかじめスクリプトとして用意しておいた以下のfunctionを回す。
insert_if <- function(data, check_col, check_value) {
# if you need input validation
col_en <- rlang::enquo(check_col)
# ↑カテゴリー列を表す→1
is_category <- data %>%
dplyr::distinct(!!col_en) %>%
# ↑1が展開され、カテゴリー列のユニークな値を取得する
dplyr::filter(!!col_en == check_value) %>%
#↑それがcheck_valueと等しい場合、すべての行をフィルタしてしまう
# すなわちcheck_valueの値が存在すればこの結果はempty状態になる
dplyr::pull()
# ↑これがちょっとわからない
if (!rlang::is_empty(is_category)) {
# ↑上の処理の結果がemptyの場合は存在するということなので
res <- data
# ↑元のデータフレームをそのまま返すために代入
} else {
res <- tibble::add_row(data, !!col_en := check_value)
# ↑そうでない場合は存在しないということなので元のデータフレームに
# カテゴリー列(1)にcheck_value(したがってcateD)を代入した行を追加して代入
}
return(res)
}
とこんな解釈であってますかね?
また、後段部分もおそらく同様に
bind_if(data = ., check_col = “cateD”)
をステップにRコマンドとして追加し、
あらかじめスクリプトとして用意しておいた以下のfunctionを回す。
bind_if <- function(data, check_col) {
is_categroy <- any(names(data) %in% check_col)
# dataのベクトルの属性名にcheck_col(すなわちcateD)を含むものが
# 一つでもあればTRUE
if (is_categroy == TRUE) {
res <- data # 上の処理の結果TRUEだったらdateをそのまま代入
} else { # そうじゃない場合
tmp <- tibble(check_col = NA)
# ↑値がN/A一つだけのtibbleを生成
names(tmp) <- check_col
# ↑そいつのベクトルの属性名をcheck_colの内容(すなわちcateD)にする
res <- cbind(data, tmp)
# ↑元のデータに列方向で結合
# (この結果すべての行がN/Aの列が出来上がる)
}
return(res)
}
とこんな感じの理解でよいでしょうか?
Rにおける型?の概念はまだ理解が進んでいないので外しているかもしれませんが、
列名の取得がcolnames(data)でなくnames(data)なのにも意味があるのでしょうか。
あとクオートの概念は全く理解できてなくて、
前段がクオートさせるのに後段はクオートさせないのが
なぜなのかさっぱりわかりません(たぶん関数によるのでしょうか)が、
そこは、そうですね「そういうもの」と今は捉えることにします。
@Yasuhiro_Yatsuu さん
insert_if ()もbind_if ()についても、理解は問題ないと思われます!
いずれもカスタムRスクリプトとして登録しておき、ステップで使っていただく形です。
データフレームにcol1はA,A,B,Cという値をカラムがあったとして、Dがあるのか知りたいとします。
下記の部分はデータフレームからチェックするカラムcol1を取り出して、そのカラムの重複(A,B,C)を除き、指定した値(D)でフィルタします。このときにcol1にDが存在していれば、Dの1行が残りますが、ない場合は空のデータフレームになります。そしてifで判定するために「データフレームから、1つのベクトル」にpullに変換します。空の場合はemptyです。
!rlang::is_empty(is_category)は否定演算子(!ビックリマーク)がついているので、「emptyではない場合、つまり、なにか値がある場合(Dがある場合)、なにもせずにデータを返す」ことになります。
is_category <- data %>%
dplyr::distinct(!!col_en) %>%
dplyr::filter(!!col_en == check_value) %>%
dplyr::pull()
列名の取得がcolnames(data)でなくnames(data)なのにも意味があるのでしょうか。
これは特に意味ないです!colnames()でも良いと思います。
前段がクオートさせるのに後段はクオートさせないのが
これは私の書き方が悪いですね・・・もちろん、後者もクオートさせる書き方もできます。時間がなく・・・・省きました。
本来は、表現とか評価のためにクオートさせる書き方のほうが良いと思いますが、
正直、Exploratoryを使ってる場合、その問題も起こりにくいと思いますので「そんなもん」と思ってもらってもよいかと思います…なので、その関数の書き方でなくても良かったと反省しております・・・・すいません。
そもそもの問題は、これで解決しそうでしょうか・・・?
ありがとうございます!
後者のやり方を少しアレンジさせていただいてうまく動かすことができ、
たいへん助かりました。
Accessで(気合い入れと目検チェック含め)2時間かけてた作業が、
おかげさまでほぼ一回の操作にでき、
わずか15分に短縮できました
前者の部分はちょっと理解が追いついてなかったのですが、
is_category <- data %>%
dplyr::distinct(!!col_en) %>%
dplyr::filter(!!col_en == check_value) %>%
dplyr::pull()
if (!rlang::is_empty(is_category)) {
このくだりの解釈が間違ってましたね。
dplyr::filter()は()の中身がTRUEのものだけ残るということなので、
!!col_en、すなわちCate列の(ユニーク化した)値がcheck_value(=cateD)と等しい場合だけが残って、
ifは!を見逃してて、is_categoryがemptyじゃない場合に
元のデータそのまま返すんですね。
とても参考になりました!
@Yasuhiro_Yatsuu さま
工数圧縮に貢献できたみたいで良かったです!
後者のくだりはおっしゃる通りです!
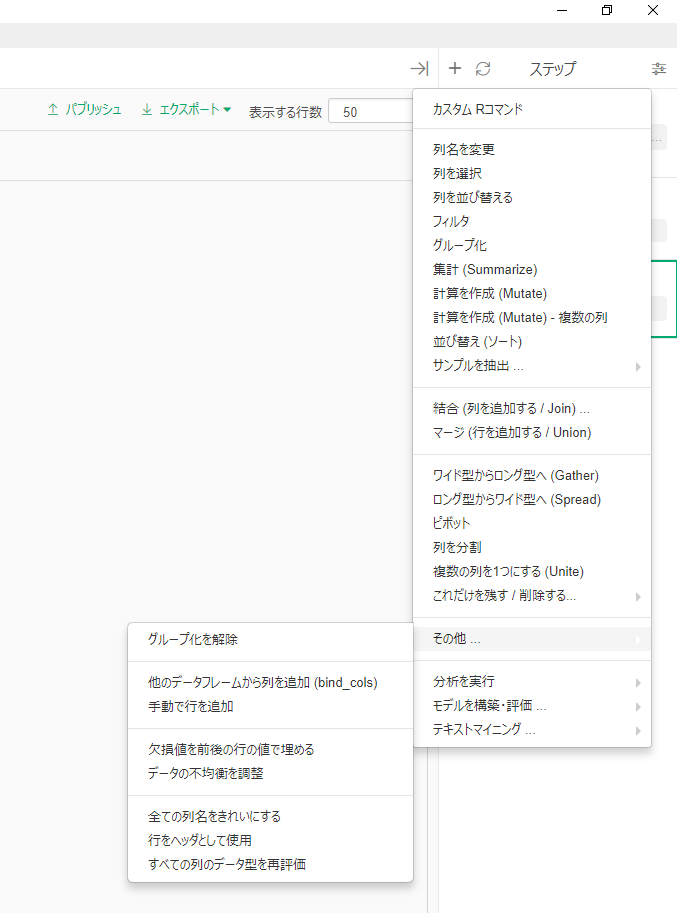
あと、前者については、関数を登録しなくても、下記のように「手動で行を追加する関数」が事前に用意されてました・・・知りませんでした。なのでこれを使えば、前者と同じようなことができるようです!
新規ステップの追加 >> その他 >> 手動で行を追加
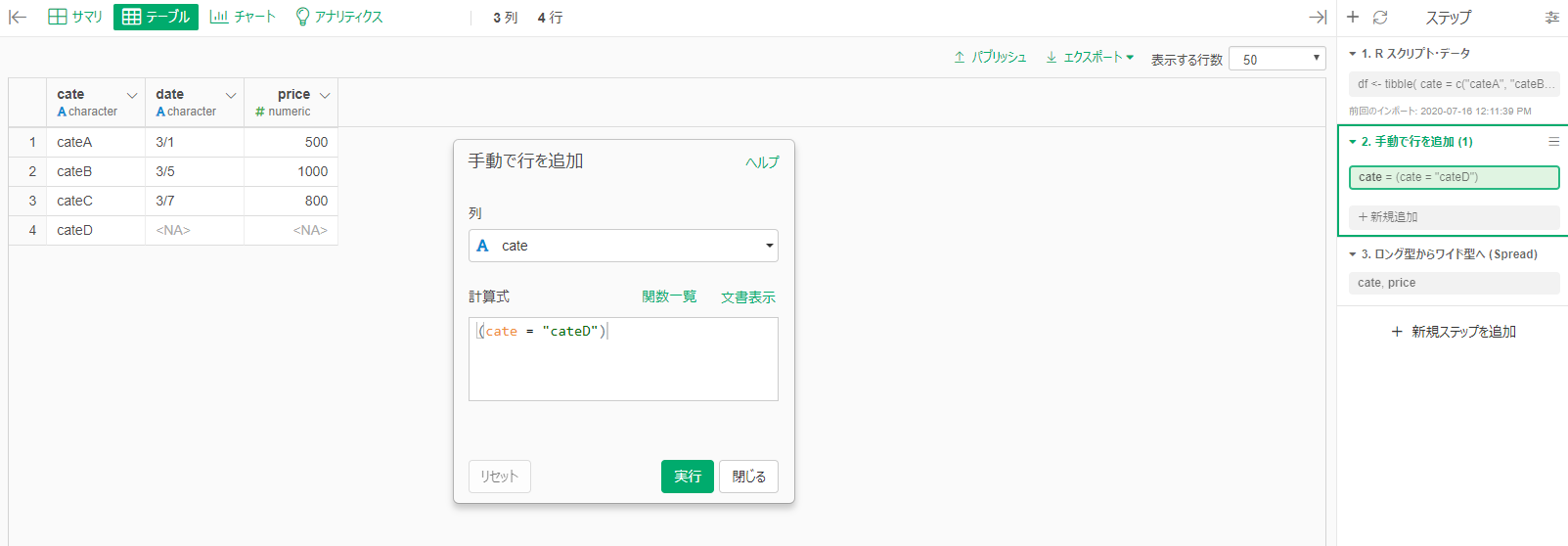
そうなんですね、それは私も知りませんでした!
ただ値を設定できる列が一つだけだと、その行の別の列の値を設定するのに
また別のステップ作らないといけないのもアレだなと思って、
Rコマンドへ変換すると
add_row(列名 = value)
ということでしたので
add_row(列名1 = 値1,列名2 = 値2)
とやると任意の行が作れることがわかりました。
ですけど、存在する場合にもダミー行作るのも正直少し気持ち悪いですし、
じゃあってんでその値が存在するかどうかチェックかけるなら、
結局前者のやり方とあまり変わらない気もします。
※pythonだとvalueAがlist1に存在するかどうかは
if valueA in list1:
で一発なのですが、Rだとそのへんのお作法がまだよくわかっていません
今回Rの勉強になったのでbind_ifでいかせていただきます!
「いいね!」 1