Exploratoryにおけるロジスティック回帰分析の統計量に関して2つ質問があります。
① ロジスティック回帰分析の変数重要度とは何でしょうか?各説明変数の標準偏回帰係数ですか?
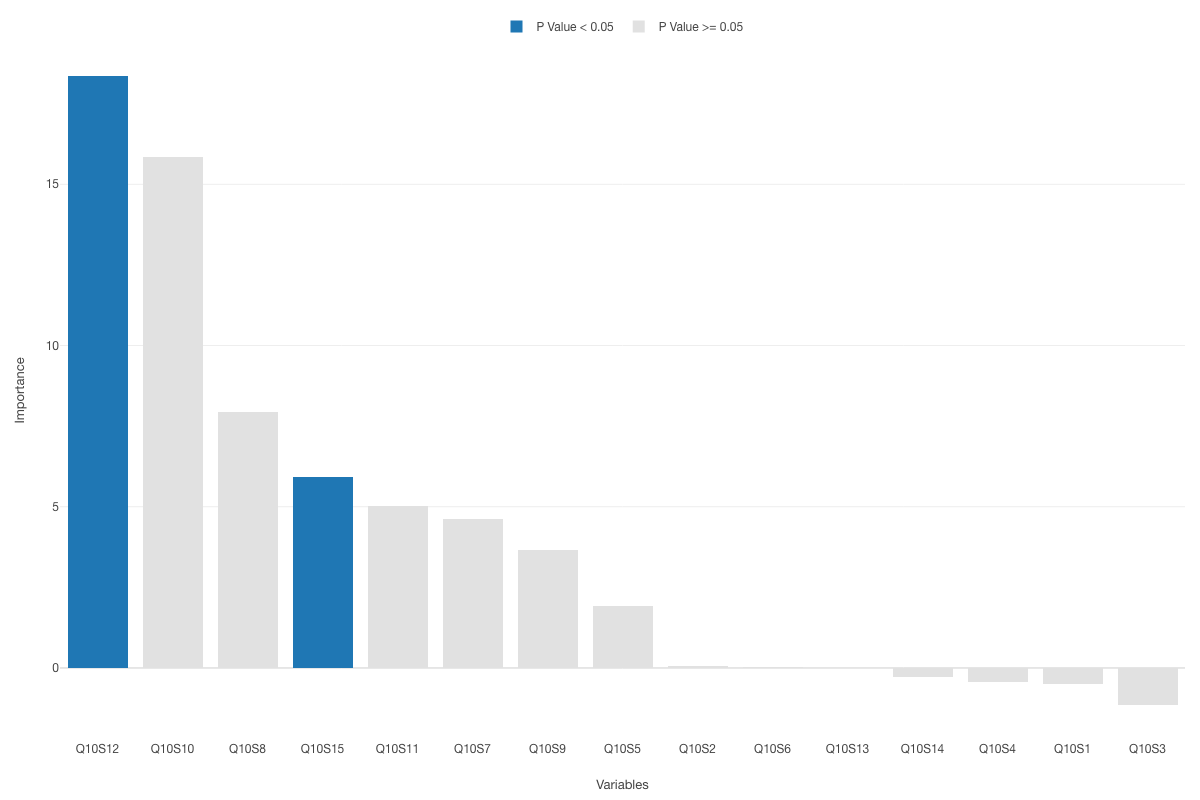
② 下記添付画像のように、変数重要度(Importance)は高いのにP値が0.05を上回るために有意でないと判断された説明変数をどう評価すれば良いのでしょうか?
説明変数としては目的変数に与える影響は大きいが、有意でない(関連性がない)という状態がよく分かりません。。。
よろしくお願いします。
Exploratoryにおけるロジスティック回帰分析の統計量に関して2つ質問があります。
① ロジスティック回帰分析の変数重要度とは何でしょうか?各説明変数の標準偏回帰係数ですか?
② 下記添付画像のように、変数重要度(Importance)は高いのにP値が0.05を上回るために有意でないと判断された説明変数をどう評価すれば良いのでしょうか?
説明変数としては目的変数に与える影響は大きいが、有意でない(関連性がない)という状態がよく分かりません。。。
よろしくお願いします。
@11127 さん
はじめまして。
① ロジスティック回帰分析の変数重要度とは何でしょうか?各説明変数の標準偏回帰係数ですか?
これは標準偏回帰係数ではなく、permutation importanceという計算手法により計算された変数の重要度いを示す値です。下記のExploratory社のセミナーでも紹介されています。
(※以降、内容が正確ではない可能性がありますので、詳細が気になるのであれば公式に問い合わせるなどしてください)
添付画像のグラフは、私の知る限りでは、permutation importanceの値を統計検定で有意かどうかをみているのではなく、おそらく変数重要度のグラフに、各変数のp値の判定をマッピングしているものだと思います。
つまり、棒グラフは変数重要度により計算された値で、有意かどうかは、ロジスティック回帰であれば、Wald testで検定された結果をカラー要素としてマッピングしているのものだと考えられます。
そのため、permutation importanceとWald testの計算方法はそもそも異なるので、結果に相違がでること自然かと思います。例えば、今回のようなpermutation importanceで重要であり、Wald testで有意ではない、という組み合わせや、それ以外にも下記のようなパターンがあり得るかと思います。左がpermutation importanceで、右がWald testと、簡略化するために重要、有意であるを○とします。
パターン1 : ○ - ○
パターン2 : ○ - ☓
パターン3 : ☓ - ○
パターン4 : ☓ - ☓
データ分析の目的や内容、それに必要な計算方法に照らし合わせて、permutation importanceとWald testの結果を解釈されればよいかと思います。
@sugiakiさん
初めまして。
ご丁寧な説明ありがとうございます。
おかげさまで色々勘違いしていたところが解消できました!!
いただいた回答を参考にして変数評価を解釈していきます!!