テキストマイニングについて教えていただきたいです。
状況としては、アイデア25案に対して、FAを取っており、その分析をしようとしています。

上の画像の様に、フィルターで案別や購入意向別でいろいろと絞ってテキストマイニングをしたいです。
現在は単語化していないので、全てが文章になってしまっています。
ですが、単語化すると全案がまとめて単語化してしまいます。
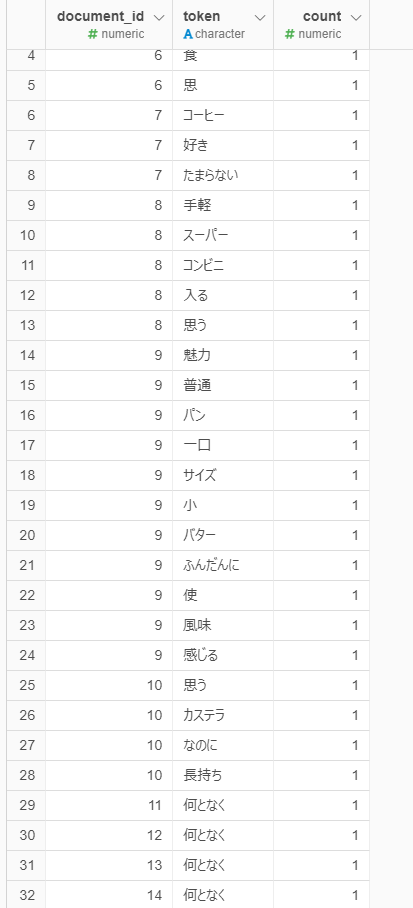
これは、表の段階で分析したい案件などでフィルターをかけておかないといけないのでしょうか?
チャートのフィルターでサクサクといろんな切り口でテキストマイニングをすることは難しいでしょうか?
何卒、宜しくお願い致します。
@Masaki_Nakazawa さん
画像のようにデータを加工すれば、チャート画面でフィルターを使ってデータをインタラクティブに絞りこむことは可能かと思います。手書きの画像で汚くてもすいません。
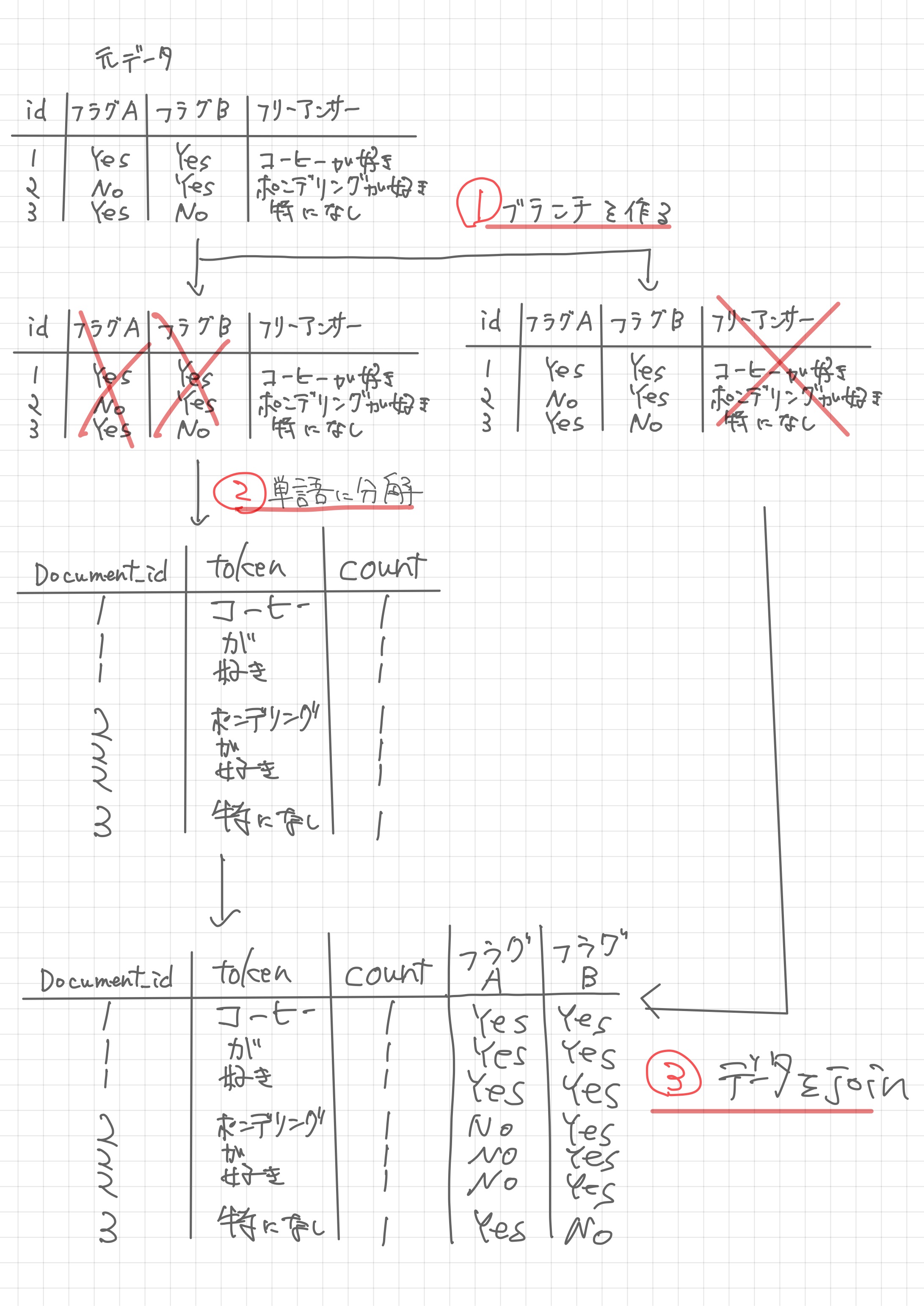
Step1 : 最終的なデータの状態を考える
画像の通り、最終的には「単語化されたデータ」に「フラグ」がついている状態であれば、チャート機能のワードクラウドでデータを絞り込めます。なので、この状態にデータを加工していきます。
Step2 : ブランチ機能でデータを分割
Exploratory のブランチ機能で、もとのデータを「①単語化するデータ」と「②フラグをもつデータ」に分割します。ブランチ機能は下記を参考にいただければと思います。
Step3 : 片方のデータを単語化(トーカナイズ)する
質問の際に提示されている画像の通り、データを単語化します。
Step4 : フラグを持つデータをJoinする
各データの「共通のキー」をもとにデータをJOINします。JOINについては下記の記事を参考にいただければと思います。各データの「共通のキー」がない場合、Step1の段階でデータの状態の合わせて作成します。1行1回答であればrow_number関数などで作成できます。アンケートデータであれ、回答者を識別するためのID列があるはずです。
いかがでしょうか?
「いいね!」 1
わざわざ手書きでお答えいただきまして有難うございます!
感動です!!
このような発想が出てくるのがすごいです・・・
大変参考になりました!!
有難うございました!!
「いいね!」 1