重回帰分析の"変数重要度"における素朴な疑問です。
ブートキャンプの資料の変数重要度の算出方法のところに、"「役に立たないもの」という状態を作るために、それぞれの変数をランダムにシャッフルする。"という記述がありました。
ここの"ランダムにシャッフル"の部分ですが、ランダムということは、違う統計ソフトを使用したり、同じ統計ソフトで同じデータを使ってもデータの行の順番を変えれば、ランダムでシャッフルされたときの変数の組み合わせが変わり、変数重要度が若干変わってくるといったことは起こり得るのでしょうか?
ランダムということは、全パターンの組み合わせを実行しているわけではないですよね…?
基本的な原理がしっかり理解できておらずお恥ずかしいのですが、ご回答のほど宜しくお願いいたします。
@Masaki_Nakazawa さん
ここの"ランダムにシャッフル"の部分ですが、ランダムということは、違う統計ソフトを使用したり、同じ統計ソフトで同じデータを使ってもデータの行の順番を変えれば、ランダムでシャッフルされたときの変数の組み合わせが変わり、変数重要度が若干変わってくるといったことは起こり得るのでしょうか?
・違う統計ソフトについて
変数重要度(Permutation Importance)の計算が、同じアルゴリズムで同じように計算されるコードとして記述されており、かつ、計算の中で「ランダム」に動く部分の挙動が、統計ソフト間で同じであれば、同じ結果は返されると思いますが、基本、違う統計ソフトを使用するのであれば、少なからず結果の数値は変わってしまうと思ったほうが良いかと思います。
・同じ統計ソフトで同じデータを使ってもデータの行の順番を変える
ExploratoryのベースであるRには「ランダム」の動きを固定する乱数種を設定できます。sample.int()はランダムに整数を返す関数ですが、乱数種(ここでは517)を固定することで、ランダムの動きが同じになります。
> sample.int(10, 5)
[1] 3 6 2 8 9
> sample.int(10, 5)
[1] 1 3 6 2 8
> set.seed(517);sample.int(10, 5)
[1] 3 2 1 5 9
> set.seed(517);sample.int(10, 5)
[1] 3 2 1 5 9
> set.seed(517);sample.int(10, 5)
[1] 3 2 1 5 9
アナリティクスビューの重回帰分析の"変数重要度"においても、「ランダムシード」は設定できるので、シードを固定していれば、同じデータに対しては同じ変数重要度が返されるはずです。
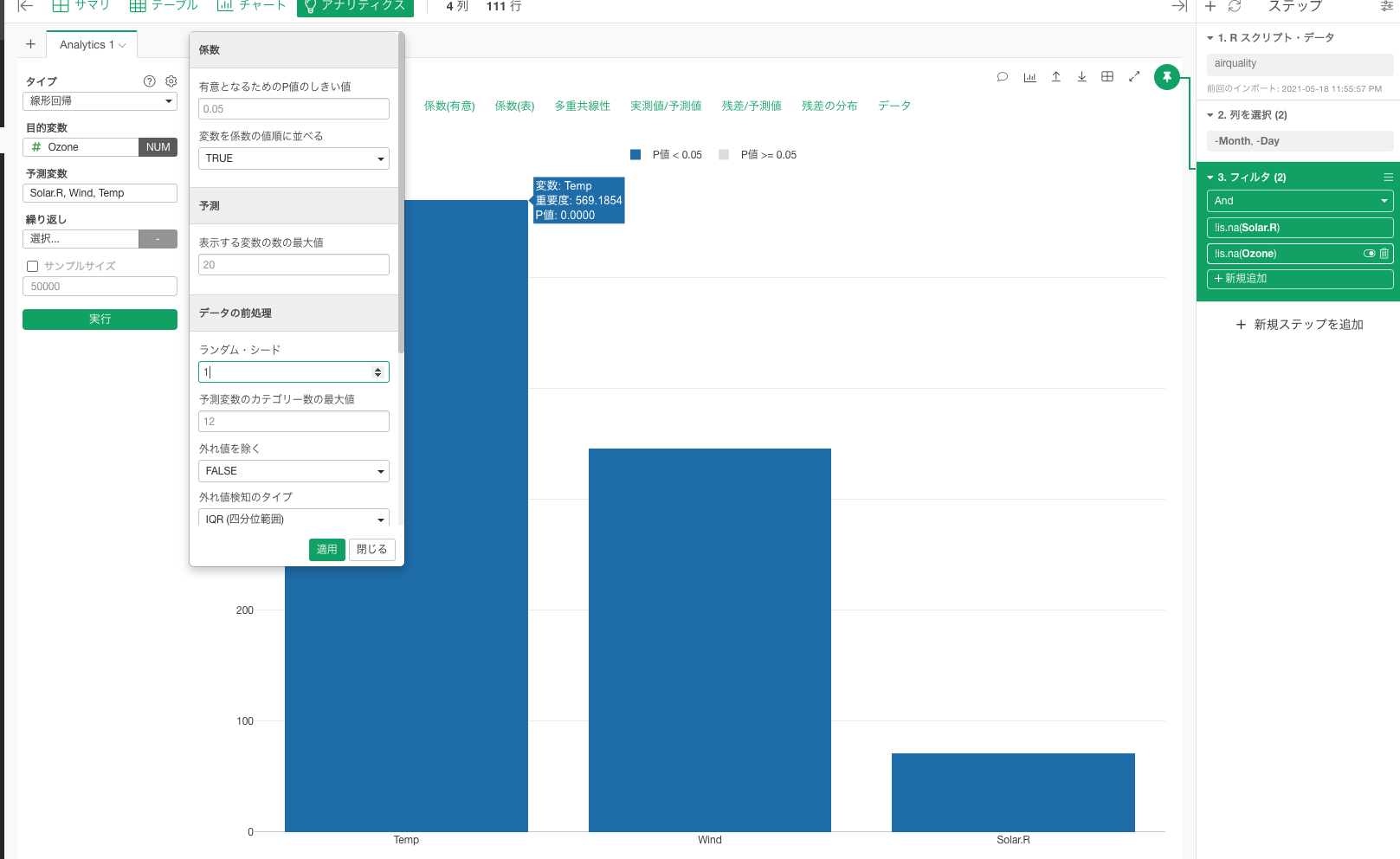
ご指摘の通り、同じデータであっても、行をシャッフルしたデータに対して「変数重要度」を計算すれば、同じシードでも、異なる結果が返されることになるかと思います。行をシャッフルする前は、左端の変数の重要度は569.1854でしたが、
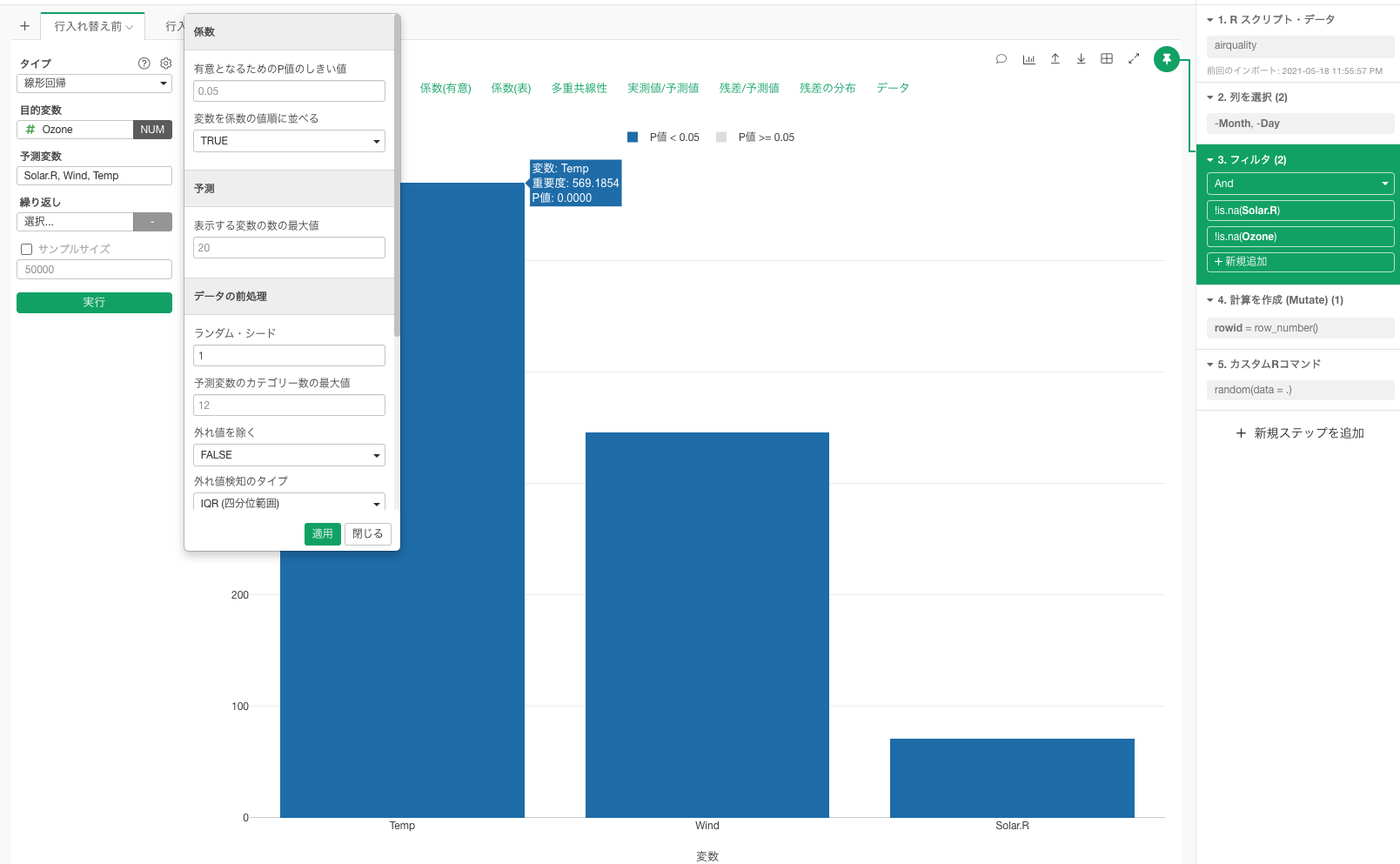
行をシャッフルした後では、行の順序関係の影響を受けない回帰係数などは、シャッフルしても変わりませんが、左端の変数の重要度は439.6379となります。
ご回答有難うございます。
すごく分かりやすいです!!
ちなみに、シードの数字は何を表しているのでしょうか?知識不足でお恥ずかしいです。
あと、ふと思ったのは同じデータでも行の順番の違いで数値が変わるなら、自分の都合のいい数値になるように何回も入れ替えて数字を出す人とかもいそうですね・・・
そんなに大きくは変わらなそうですが・・。
@Masaki_Nakazawa
Rのシードの値は整数であればOKなので517は、5月17日にこの質問の回答しよう(実際、投稿したのは5月19日ですが…)と下書きを書いてたので、その日付から持ってきた値です。 なので特段の意図はありません。
あと、ふと思ったのは同じデータでも行の順番の違いで数値が変わるなら、自分の都合のいい数値になるように何回も入れ替えて数字を出す人とかもいそうですね・・・
物は使いようなので、いるかもしれませんね・・・。ですが再現可能性が低いデータ分析の結果を報告しても、いつか痛い目に合うのは自分なので、誠実に分析に取り組みたいものですね(自戒を込めて)。
なるほど!では数字は「5」でも「15846」でもどんな数字でも大丈夫なんですね!
とても勉強になりました!!
例えば、会員NO1-5までの情報があった場合、行の順番が「12345」と「24531」の順番にしたものでは数値が若干変わるということですよね。その時の行の順番次第で変数重要度が決まるってことですね・・。