クラスター分析をする際の進め方を教えていただきたいです。
知りたいのは、「チョコレート商品の購買視点での分類」です。
単品商品を「徳用、健康、子供向け、大人向け・・・」のような分類ができればと考えています。
インターネットで検索しても得たい結果やパターンが違ったりするのでイマイチピンとこず…
こんな感じかな?と自分で考えているのが以下になります。
■単品×単品の併買率をクロス表などで取得 ⇒ そのままクラスター分析へ
■単品×単品の併買率をクロス表などで取得 ⇒ 主成分分析で単品をいくつかの括りでまとめる ⇒ その括りでクラスター分析
自分で進めたことがなく、
ちなみに単品商品は50-100品くらいです。
ご教授のほど、何卒宜しくお願いいたします。
@Masaki_Nakazawa
ちなみに単品商品は50-100品くらいです。
どのようなデータがあるのかわからないので、データを勝手に推測して話を進めさせていただきます。おそらくIDPOSやチョコレートを扱うECの注文データだと思われますので、その前提で記載します。
チョコレート商品50-100品の特徴について、アンケートで商品の特徴を回答させてデータを取得するのは個人的には想定し難いのためです。
アプローチする方法はたくさんあると思いますが、個人的にはチョコレート各商品ごとに、特徴量を地道にデータ加工して作成していき、クラスタ分析を行えば、やりたいことは実現できるように思えます。
例えば、小売の複数の店舗を分類する例であれば…店舗ごとに店舗情報や注文データから下記のように特徴量を地道にデータ加工して作り出していき、クラスタ分析をかけて、店舗をグループ分けするイメージです。
- 最寄り駅までの距離
- 店舗からの数km以内の世帯情報
- 売り場面積
- 駐車場の駐車台数
- 会員比率
- リピートユーザー
- 客単価
- お客の年代
- 性別比率
…
用意する特徴量の数や内容は分析の目的に応じて変わってくるかと思いますし、分析結果から施策を検討し、売上に貢献できるような分析結果を得られるモデルを作ればよいかと思います。
説明のために簡略化(性別(0=female, 1=male)、年代、値段だけ使います)していますが、下記のような注文データがあったします。説明用に使ったデータなので、細かい部分が整合性ないですが、回答には影響しないので、無視してください。
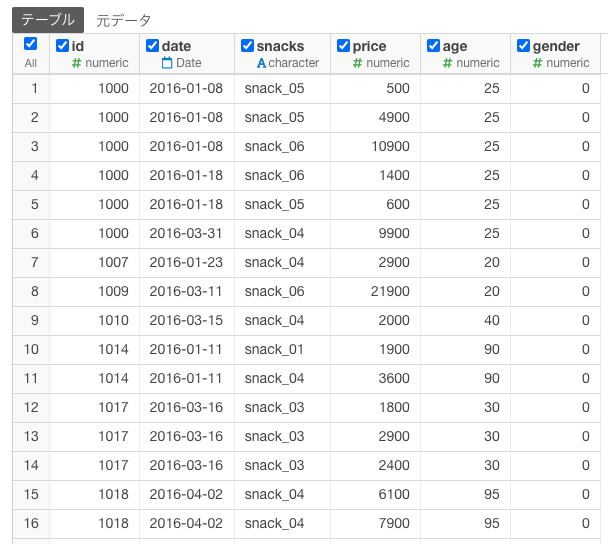
例えば各チョコレート(snack01~18)を「性別、年代、値段」を特徴として、各チョコレートをグループ分けするために下記のようなデータを作りました。
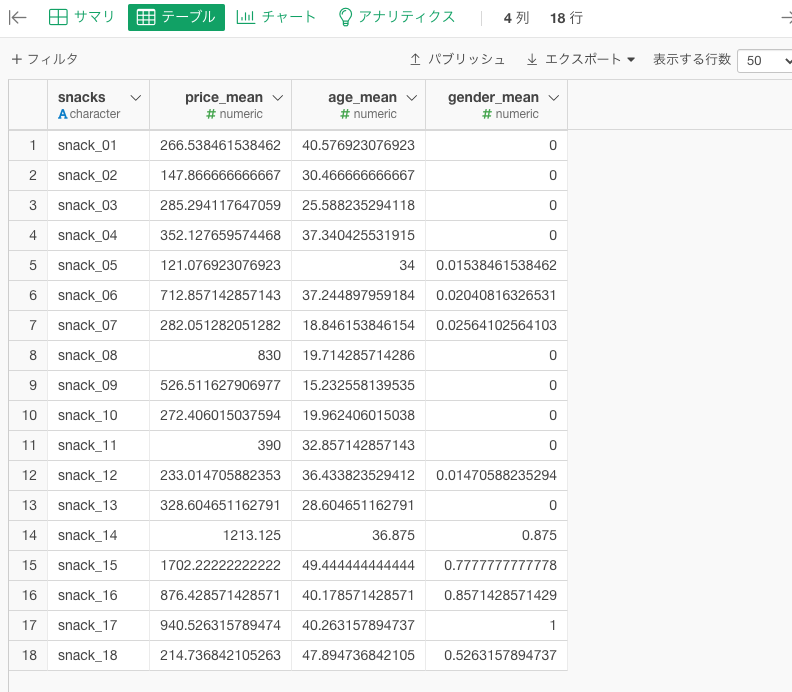
クラスタ分析を実行すると下記の画像の結果が得られます。ざっくりと解釈すると、オレンジ(クラスタ2)のsnack07~10は特徴として「年代が若い女性が好み、安い」チョコレートが分類されていることがわかります。
また、青いグループ(クラスタ1)は、「年齢が高く、男性が好み、価格が高い」チョコレートが分類されていることがわかります。Exploratoryでのクラスタ分析の解釈の仕方については、Exploratoryの西田さんが解説された動画がどこかにあったかと思います…たぶん、どこかで見たような気がします。
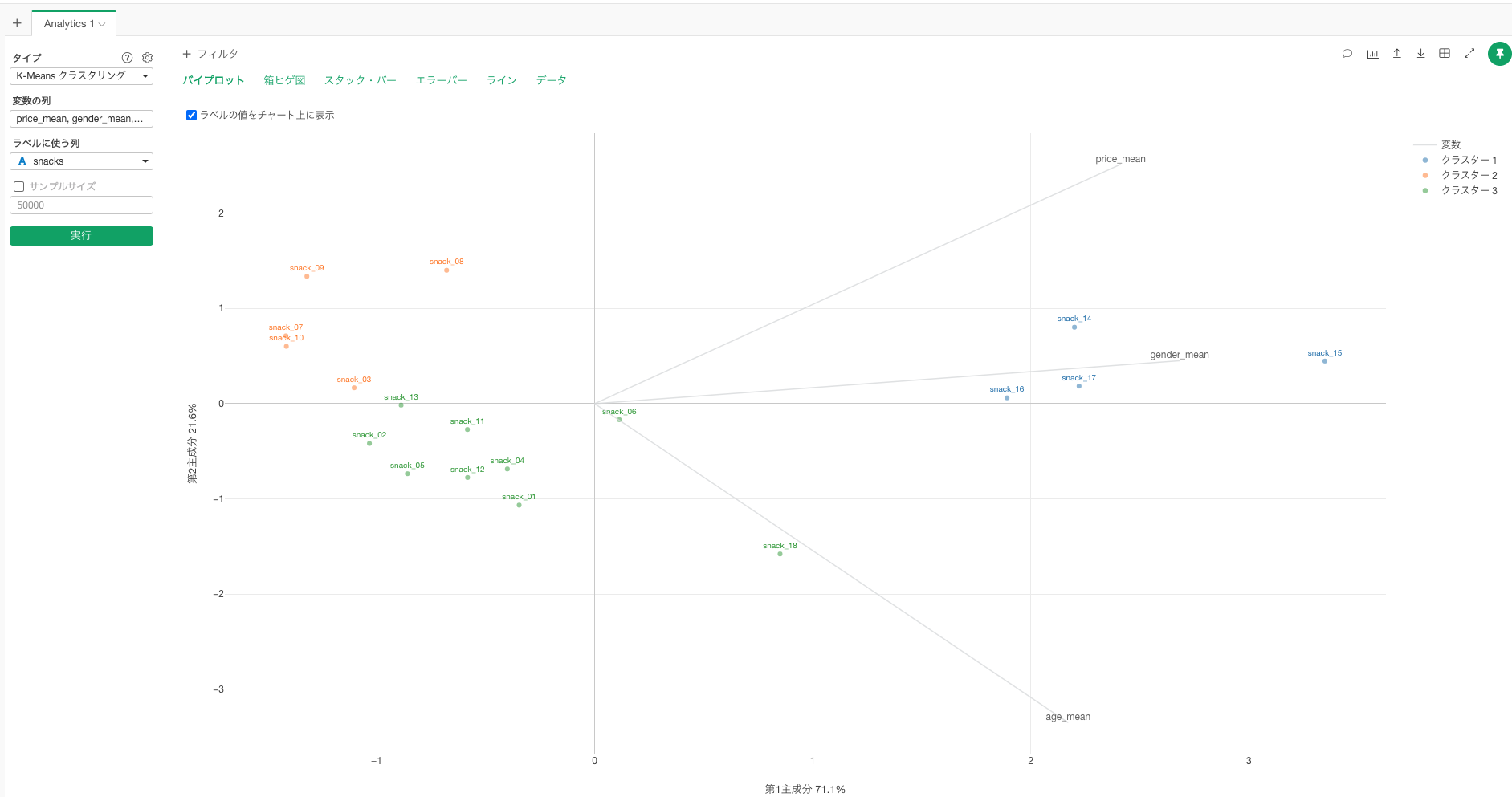
実際にクラスタの情報を、もとの注文データにJOINして戻して、クラスタごとに集計すると、先程のチャートの結果を支持するような値が計算されています。
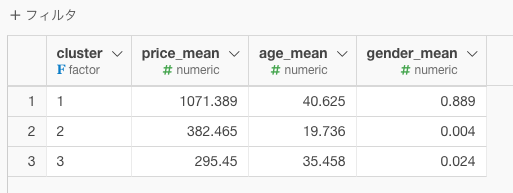
単品商品を「徳用、健康、子供向け、大人向け・・・」のような分類が
クラスタ1(青グループ)の「平均単価は1000円、平均40歳、男性がよく買っている(1に近ければ男性としているので)」という特徴を持つチョコレートグループなので、上記の例でざっくり判断すると、「大人向け」といえなくもないですし、クラスタ2のチョコレートは「若い女性が好む」チョコレートなので、「女性向け」ともいえなくないかと思います。
分類したい結果を表現するような特徴量(※)を考えて、作って、クラスタ分析を行えば、分析目的は達成できるかと思いますので、何かの参考になれば幸いです。
※複数あるチョコレートを若者向けなのか、高齢者向けなのかに分類したいのであれば「年齢」を特徴として利用する、という意味あいです。
有難うございます。
丁寧なご説明も、過去の紹介ページの記載も非常に助かりました。
スギアキさんのようなやり方もあるなととても参考になります!
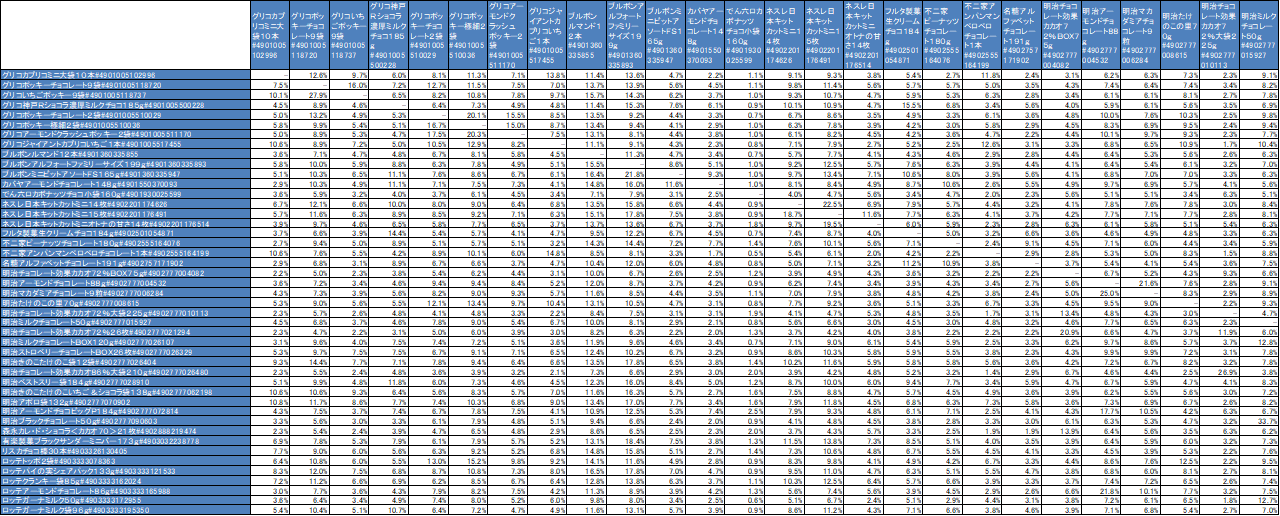
もともとは、以下のような商品ごとの併買率から一緒に買われているもの=特徴が似ているものとして、
クラスター分析をしようと思ってましたが、性年代や職業などデモグラフィックな切り口で見ても面白いなと感じました。
また、ヤスヒロさんに記載していただいた資料内で、数値を正規化しているのですが、
これは基本的にしたほうが良いのでしょうか?もしくは資料のときは変数の値の差が大きかったので
正規化する必要があったけども、そうでなければ基本的には必要ないものなのでしょうか?
ここも教えていただけますと幸いです。
何卒、宜しくお願いいたします。
ちなみに、クラスター分析はIDPOSを元にやろうとしています。
@Masaki_Nakazawa さん
これは基本的にしたほうが良いのでしょうか?もしくは資料のときは変数の値の差が大きかったので
正規化する必要があったけども、そうでなければ基本的には必要ないものなのでしょうか?
例えば、kmeansというクラスタリング分析は、「距離」を計算の過程で使用するため、大雑把になりますが、特徴量の中に極端にスケールの違うものが混じっていると、その特徴量の影響を受けて、分類がうまくできない場合があったりします。そのため、特徴量を標準化し、スケールを揃える工夫をしてから距離を計算します。
もちろん、各特徴量のスケールがすべて同じなのであれば、必要ないかもしれませんので、分析の際に使用する特徴量がどのようなものかによって判断されればよいかと思います!
検索すればいろんな方が解説されているので、詳細が気になる場合は検索していただければと思います。