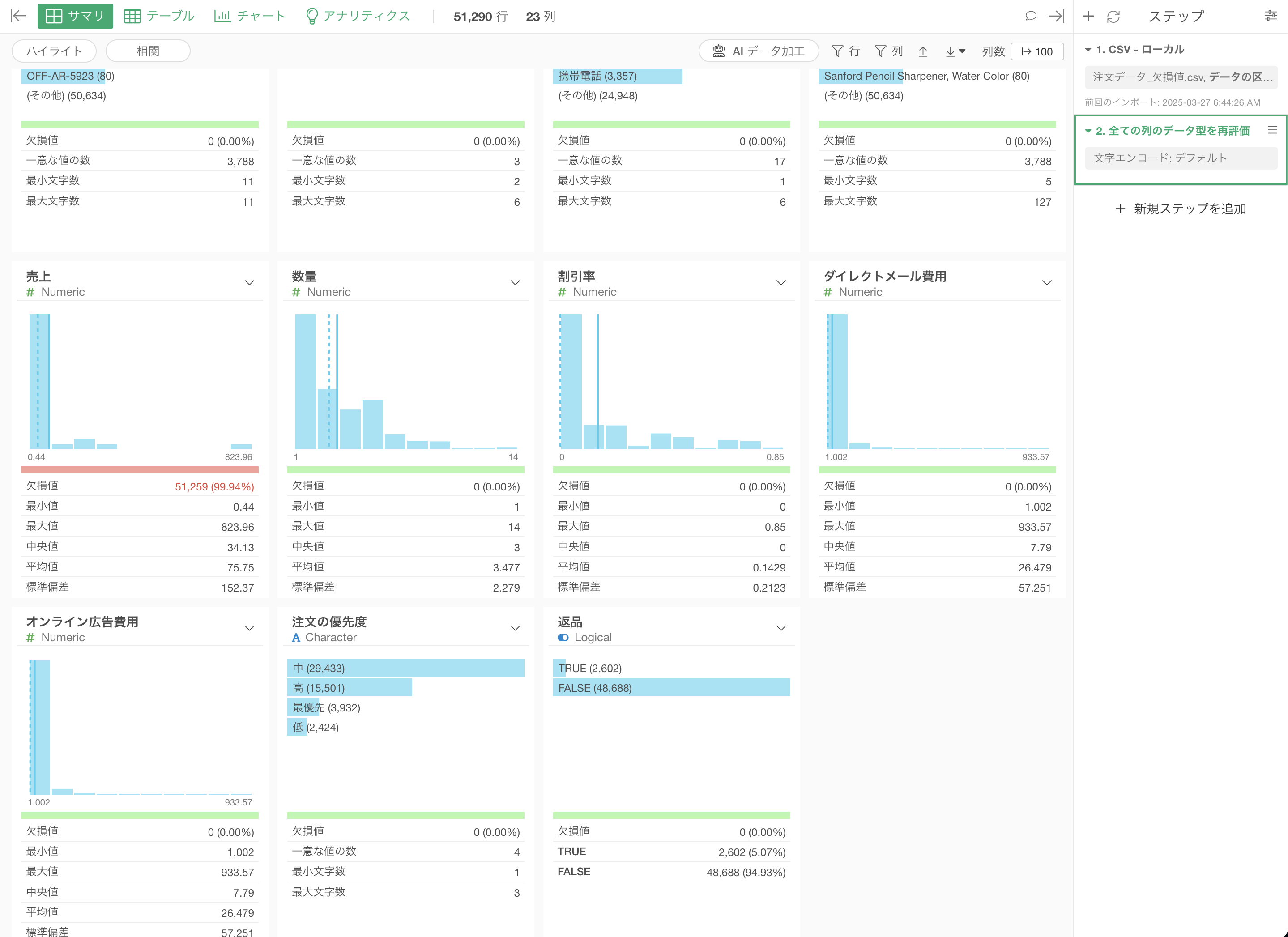
Exploratoryでは、CSVやExcelファイルなどをインポートする時に、データ型の自動認識機能により列の値に合わせて自動的にデータタイプが識別されるようになっています。
このインポートダイアログでは、最初の1000行をサンプリングしてプレビューを表示します。このサンプリングに基づいてデータ型の自動認識した結果が表示されていますが、最初の1000行がすべて欠損値である場合、その列はロジカル型として認識されてしまいます。
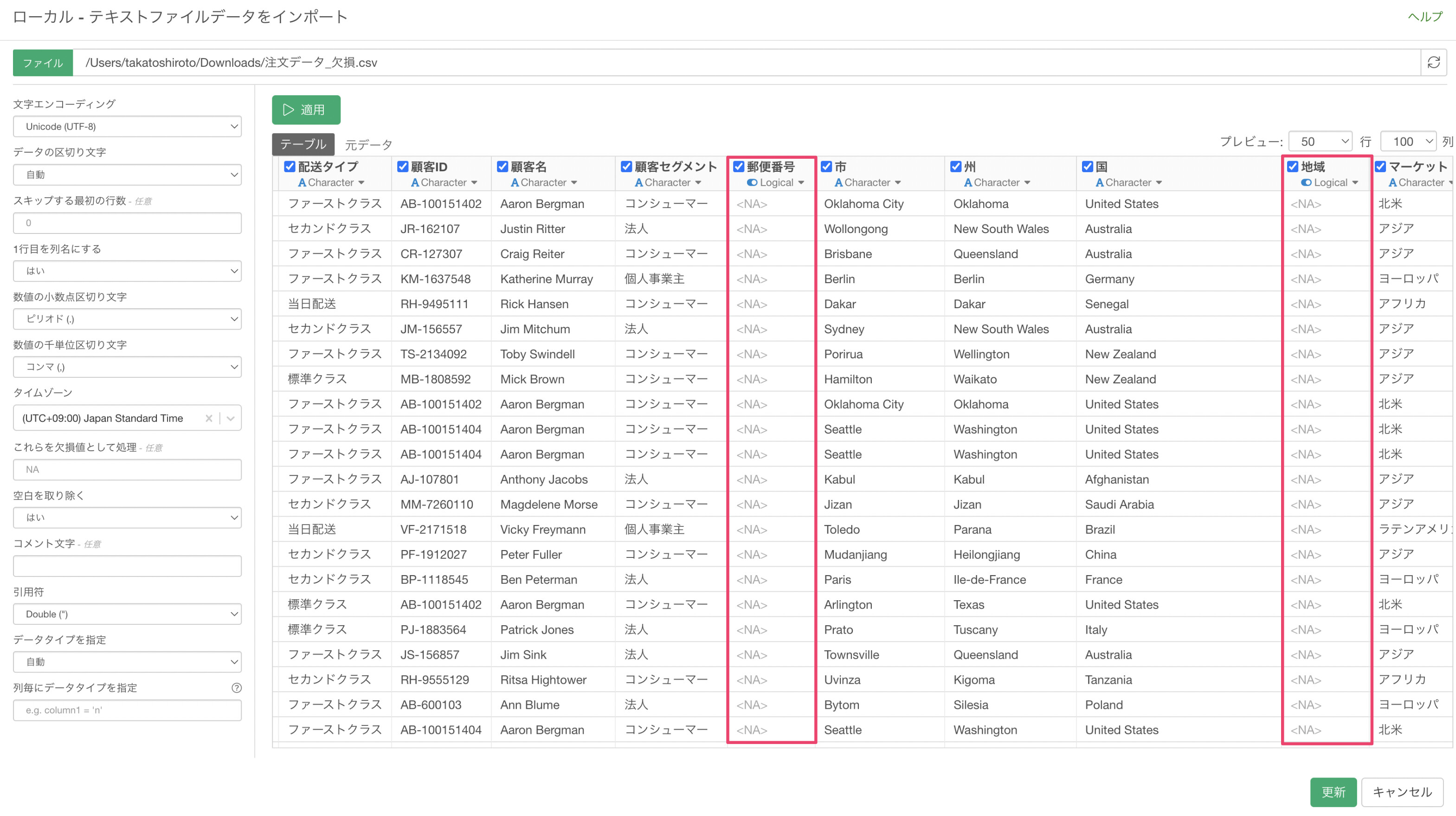 しかし、インポート実行時には再度データ型の自動認識処理が実行されるため、列に値が含まれている場合はその値に合わせてデータタイプが識別されます。
しかし、インポート実行時には再度データ型の自動認識処理が実行されるため、列に値が含まれている場合はその値に合わせてデータタイプが識別されます。
下記の例では、インポートダイアログの時点ではロジカル型になっていた「郵便番号」は数値型に、地域の列は「文字列型」に変わっていることがわかります。
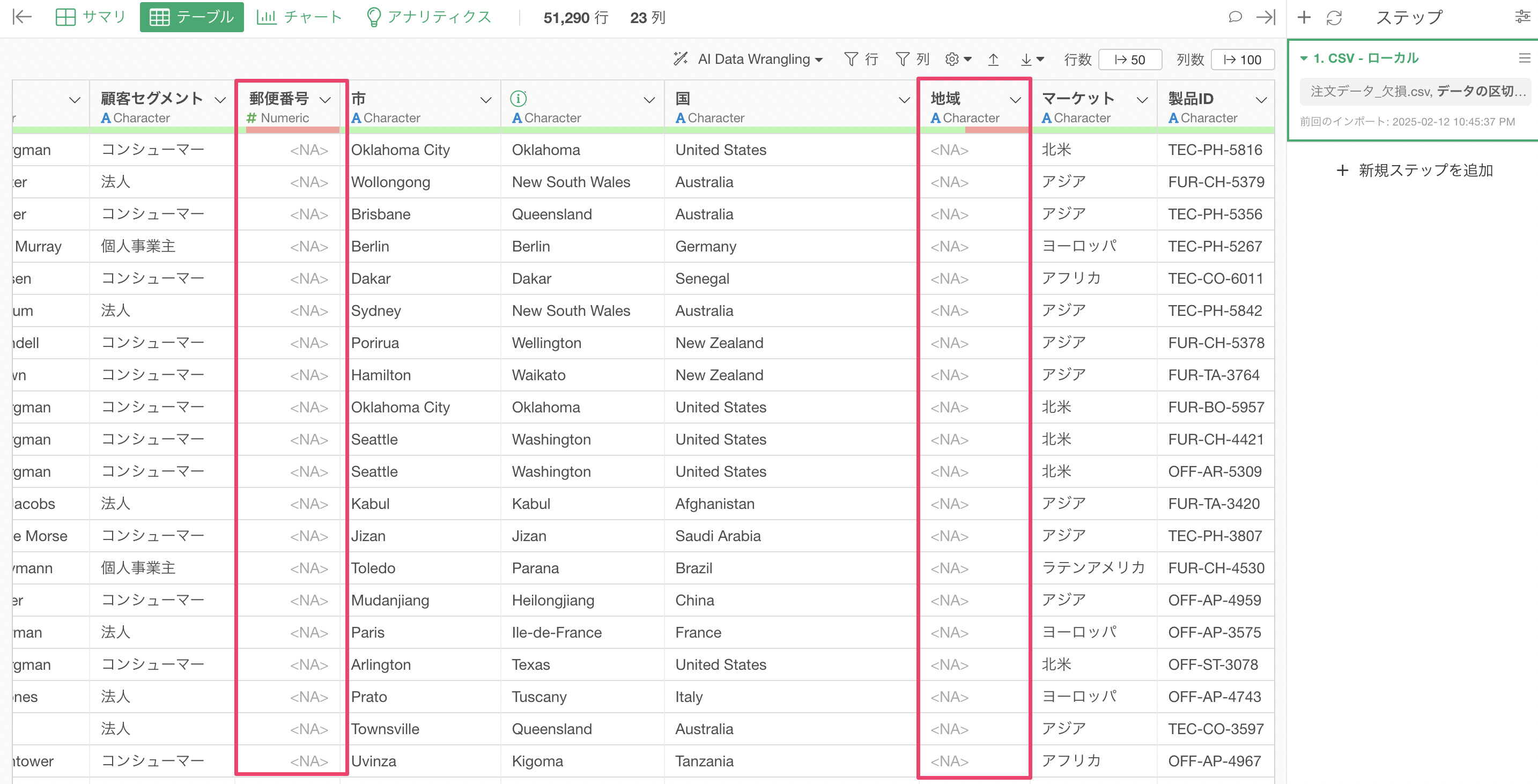
上記のことから、インポート後でもロジカル型になってしまう場合は、その列の値はすべて欠損値であるということになります。
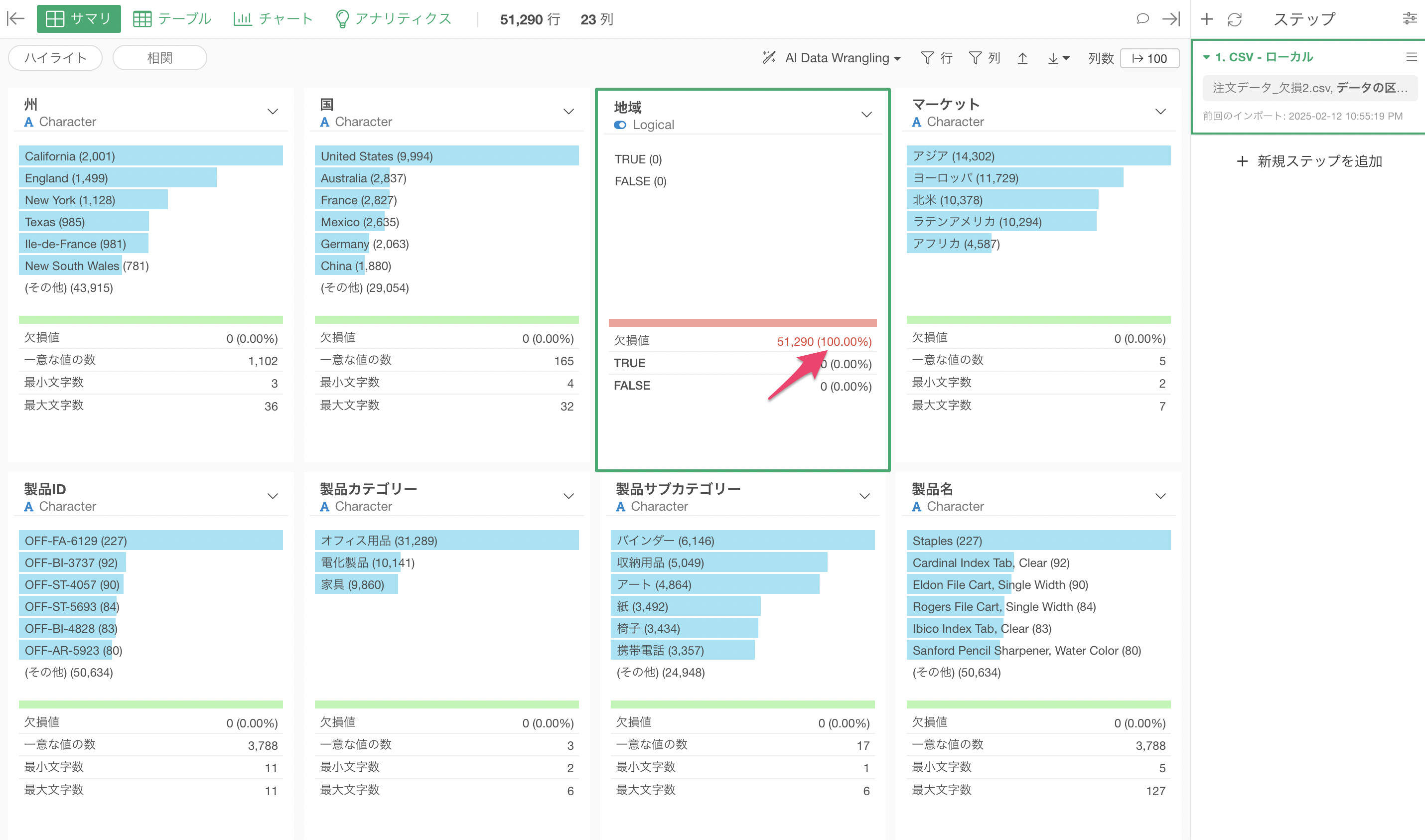
もし確認をしたい場合は、インポートダイアログ上で本来あるべきデータタイプを直接指定します。
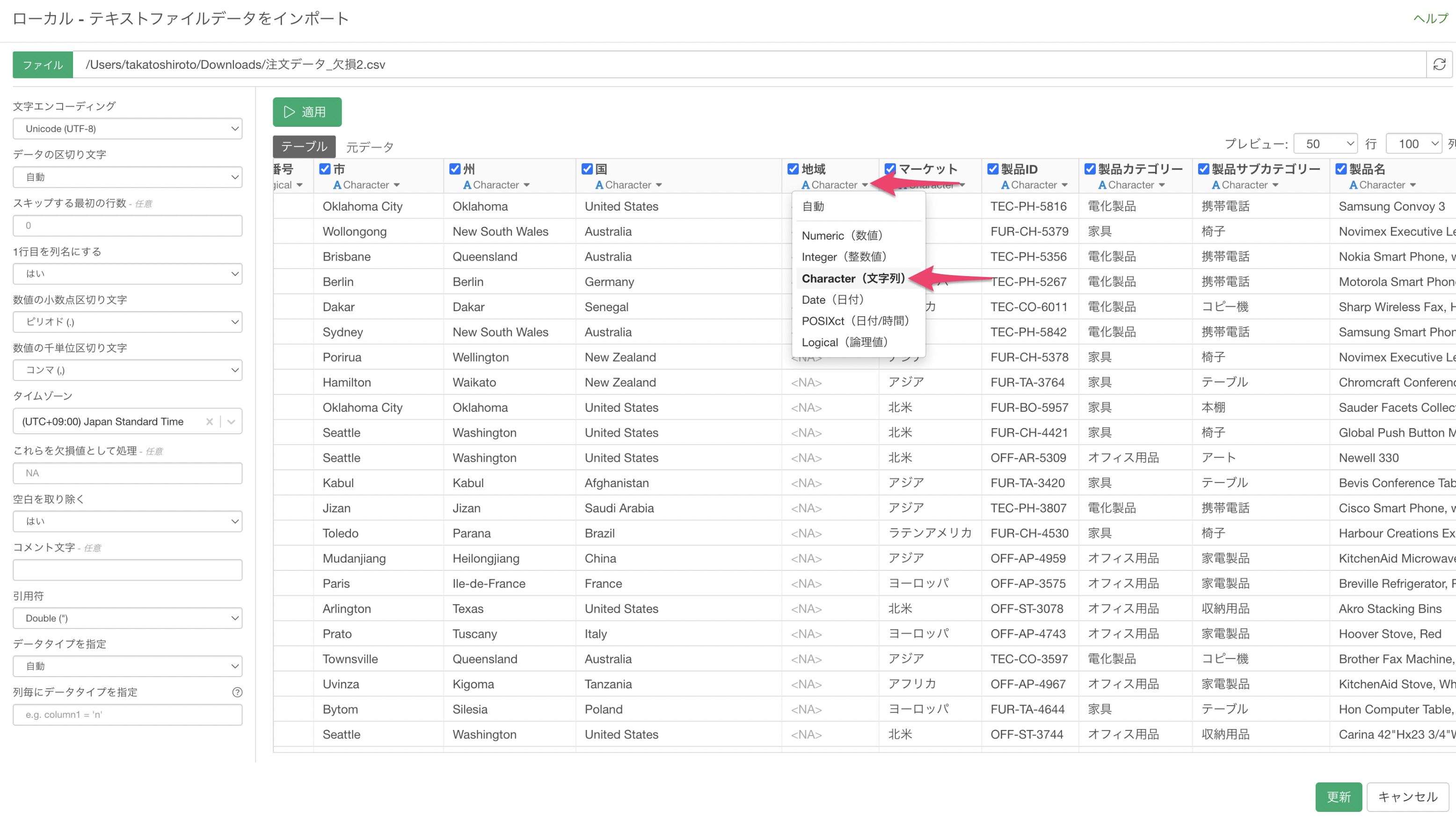 その上でデータをインポートしたとしても、その列の値はすべて欠損値であることがわかります。
その上でデータをインポートしたとしても、その列の値はすべて欠損値であることがわかります。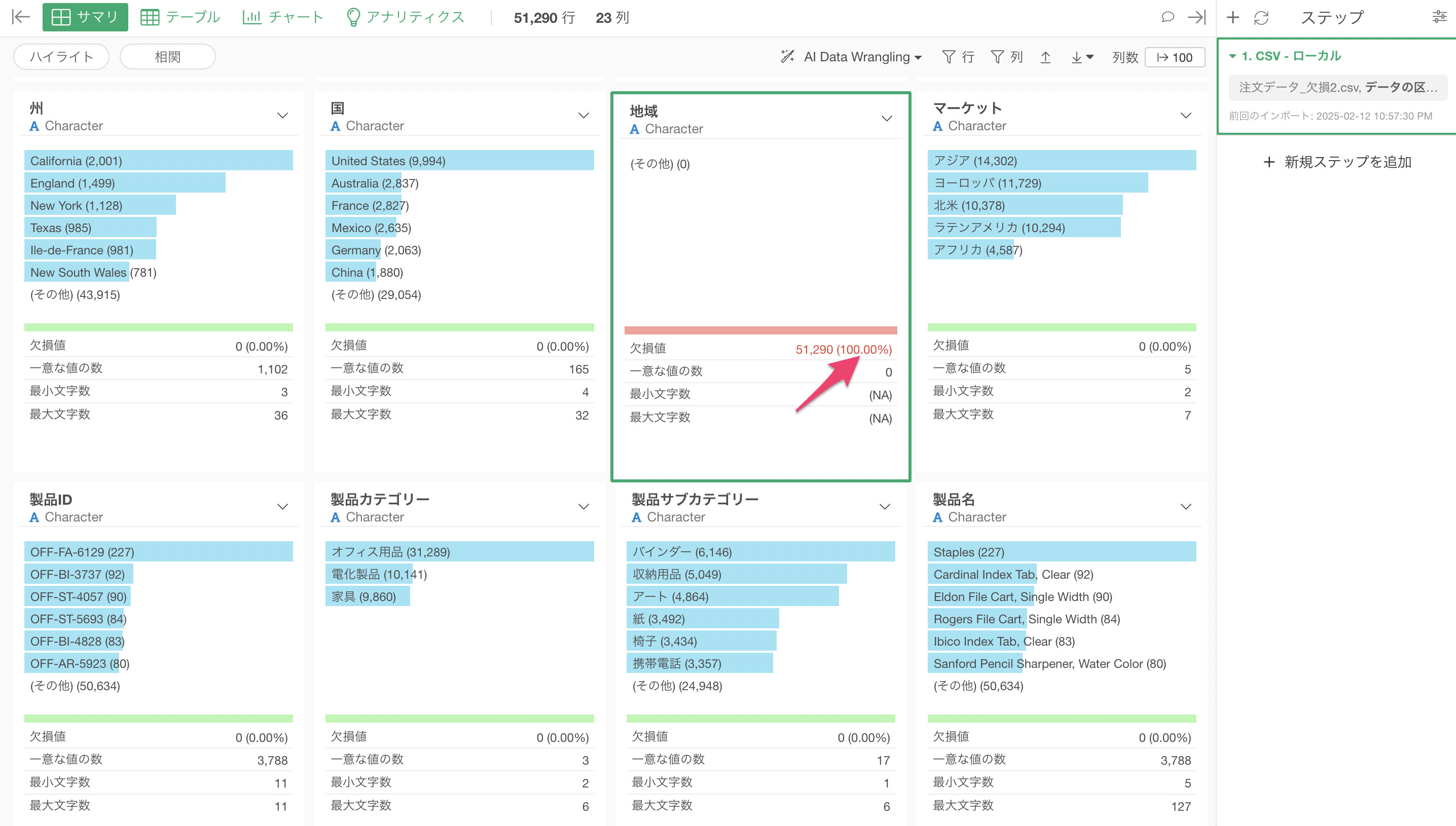
補足として、複数のCSVファイルをインポート&マージをした時に、1つ目のファイルは該当列の値が全て欠損値、2つ目のファイルは値が入っていたとします。その場合は、インポート&マージをした後にデータ型の自動認識機能が適用されるために、データタイプを固定化させたいといったニーズがなければ、個別のデータタイプ指定は不要です。
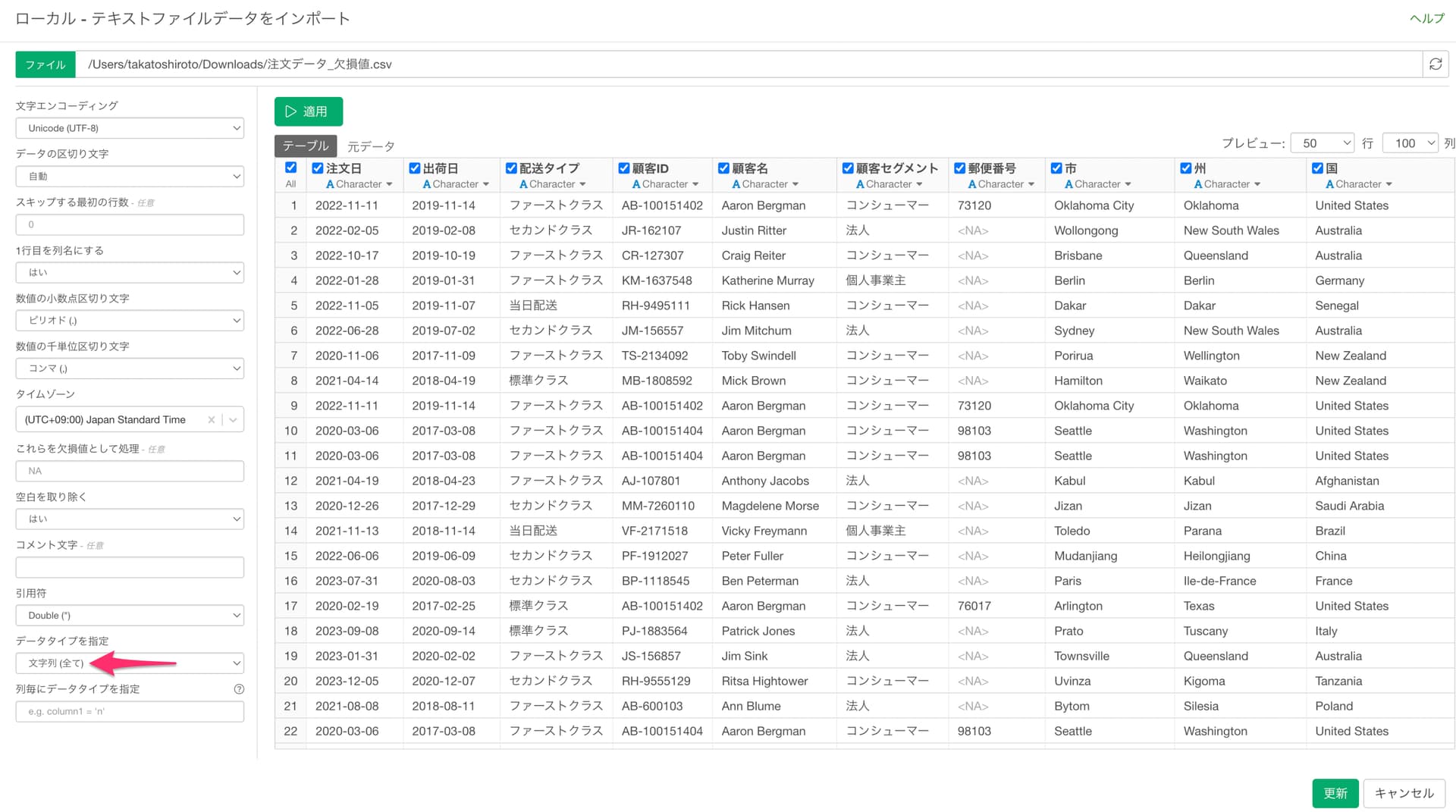
もし上記がうまく機能していない場合は、データタイプの指定に全ての列を文字列型として扱うに「はい」を指定してインポートをします。
その後に、ステップメニューのその他から「全ての列のデータ型を再評価」を実行します。
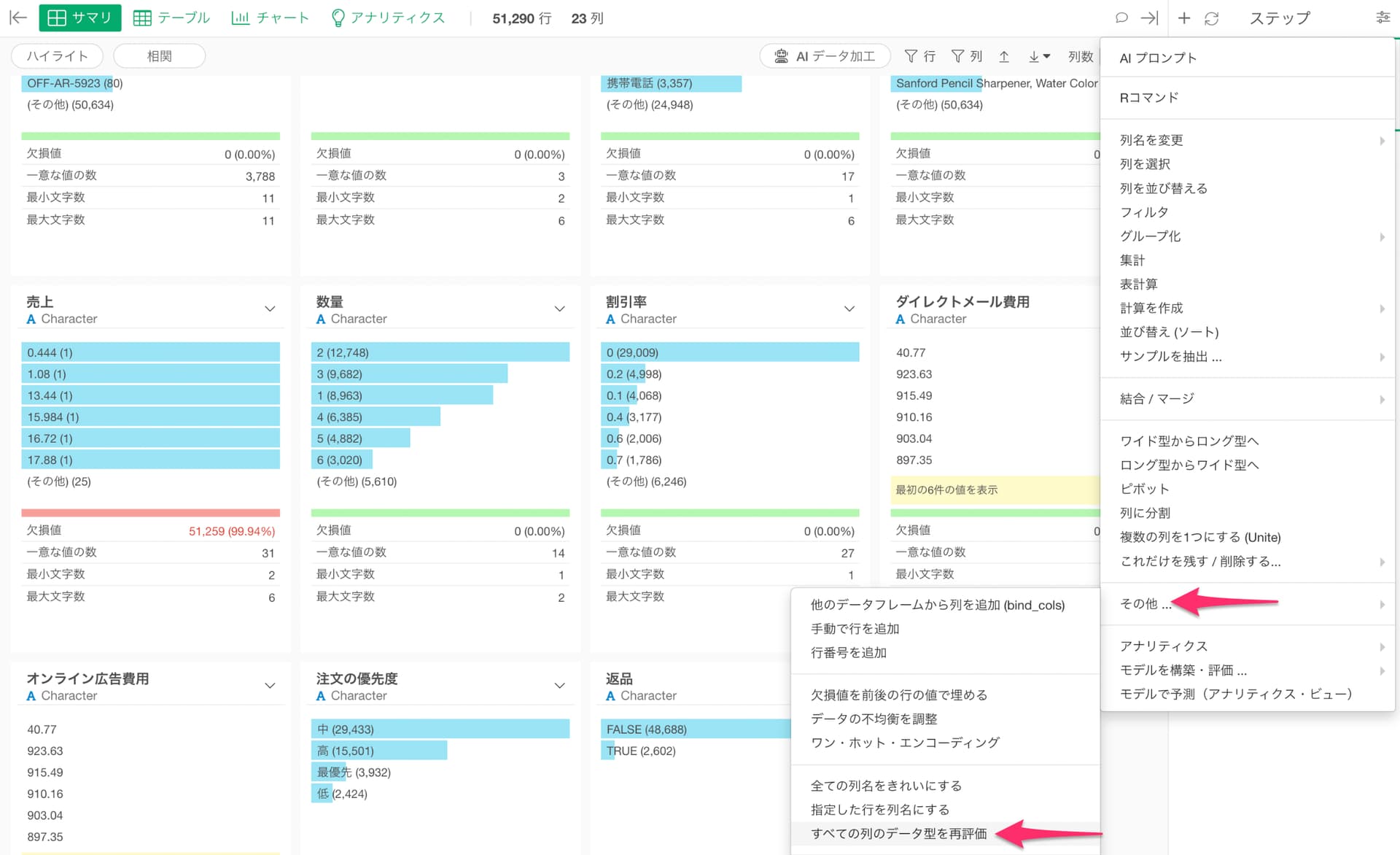
これによって、文字列としてインポートした後に、それぞれの列にある値の情報をもとにしてデータ型を自動的に識別して変換が可能です。