Exploratoryのアナリティクスビューで実行した線形回帰の結果とSPSSなどの他のツールで求められた線形回帰の結果でR2乗が異なる場合があります。
R2乗が異なる要因として考えられるものとして下記があります。
1. データのサンプル
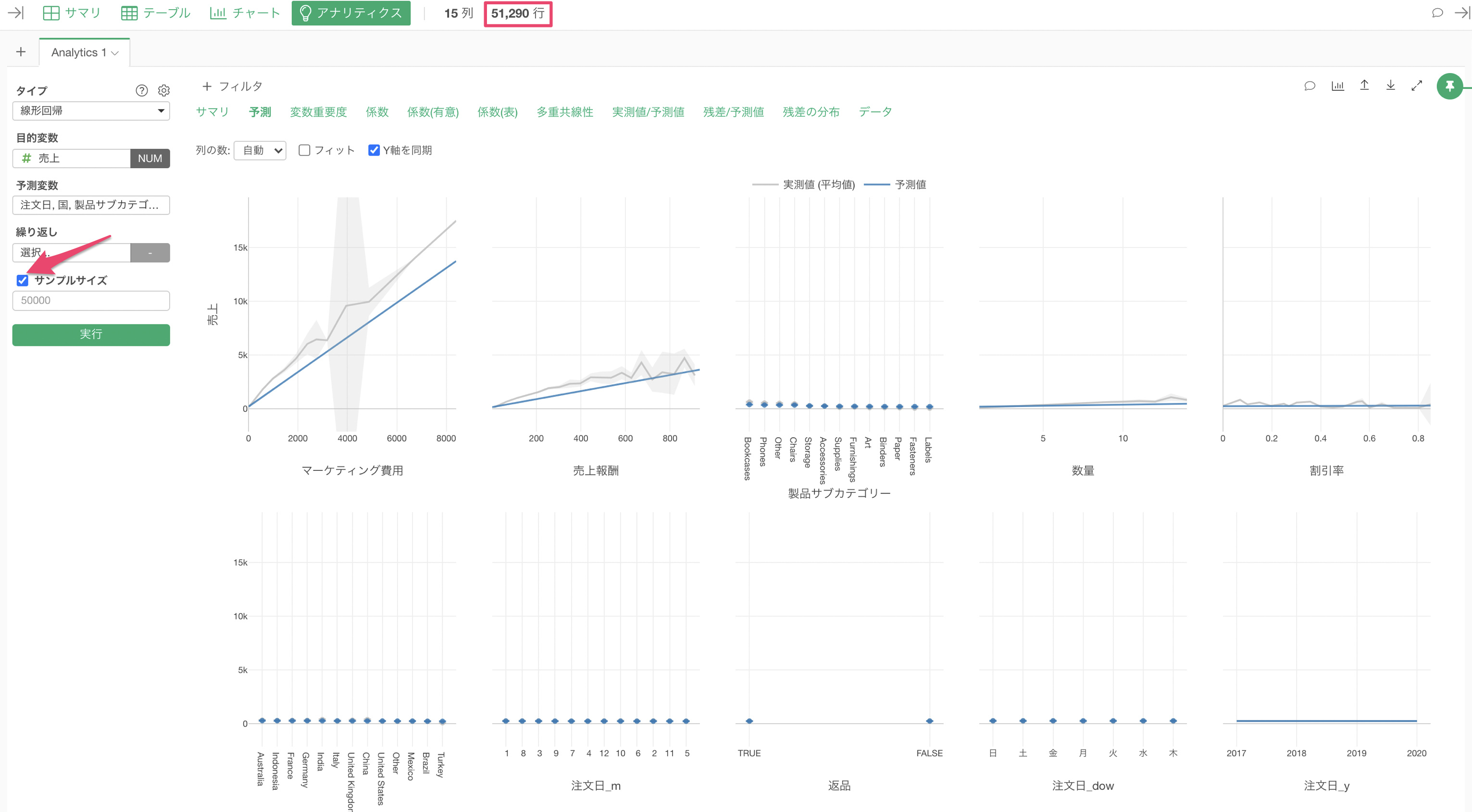
Exploratoryで線形回帰などのアルゴリズムの実行した時には、「サンプルサイズ」にチェックが付いている場合はデータを50,000行のみ使うようにサンプルして実行しています。
もし他のツールでサンプルが行われていない場合は、結果が異なるかもしれません。
サンプルするデータの行数を変更したい場合は、サンプルサイズに行数を指定する、またはチェックを外していただくことで使用するデータの行数を指定することができます。
2. 予測変数にあるカテゴリー列の扱い
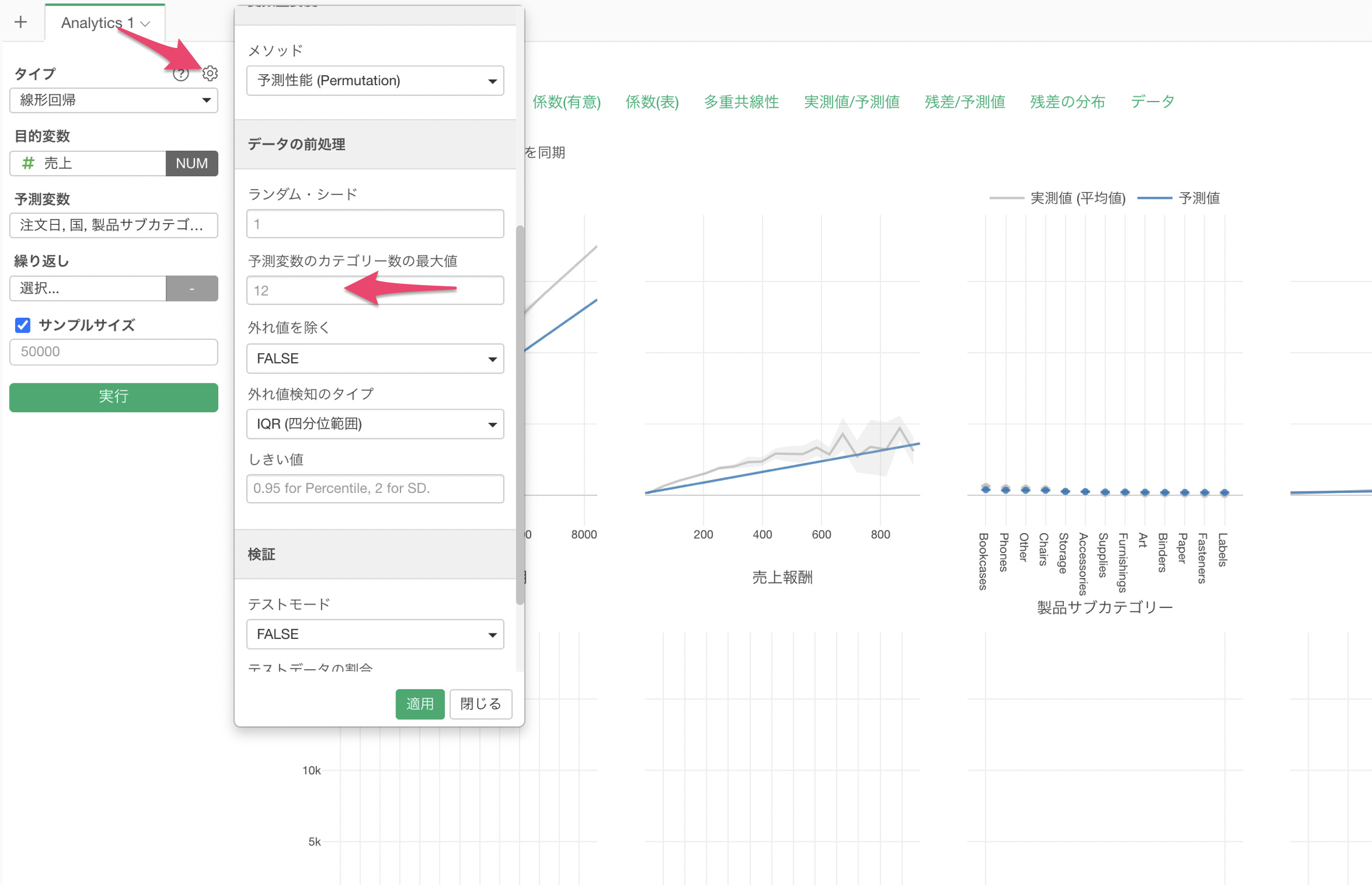
予測変数に一意な値の数が12以上だった場合は、Exploratoryの場合は行の数が多い上位12のカテゴリーとそれ以外をまとめたOtherグループとして使用しています。こちらは設定で変更が可能ですが、他のツールでのカテゴリー列の扱いが異なる場合は、R2乗に違いが出るかもしれません。
3. 欠損値の扱い
予測変数が数値の場合
Exploratoryでは数値列のデータの中に欠損値があると、欠損値を含む行を除いて線形回帰などのアルゴリズムを実行しています。
例えば、年齢の列に187行の欠損値があったとします。
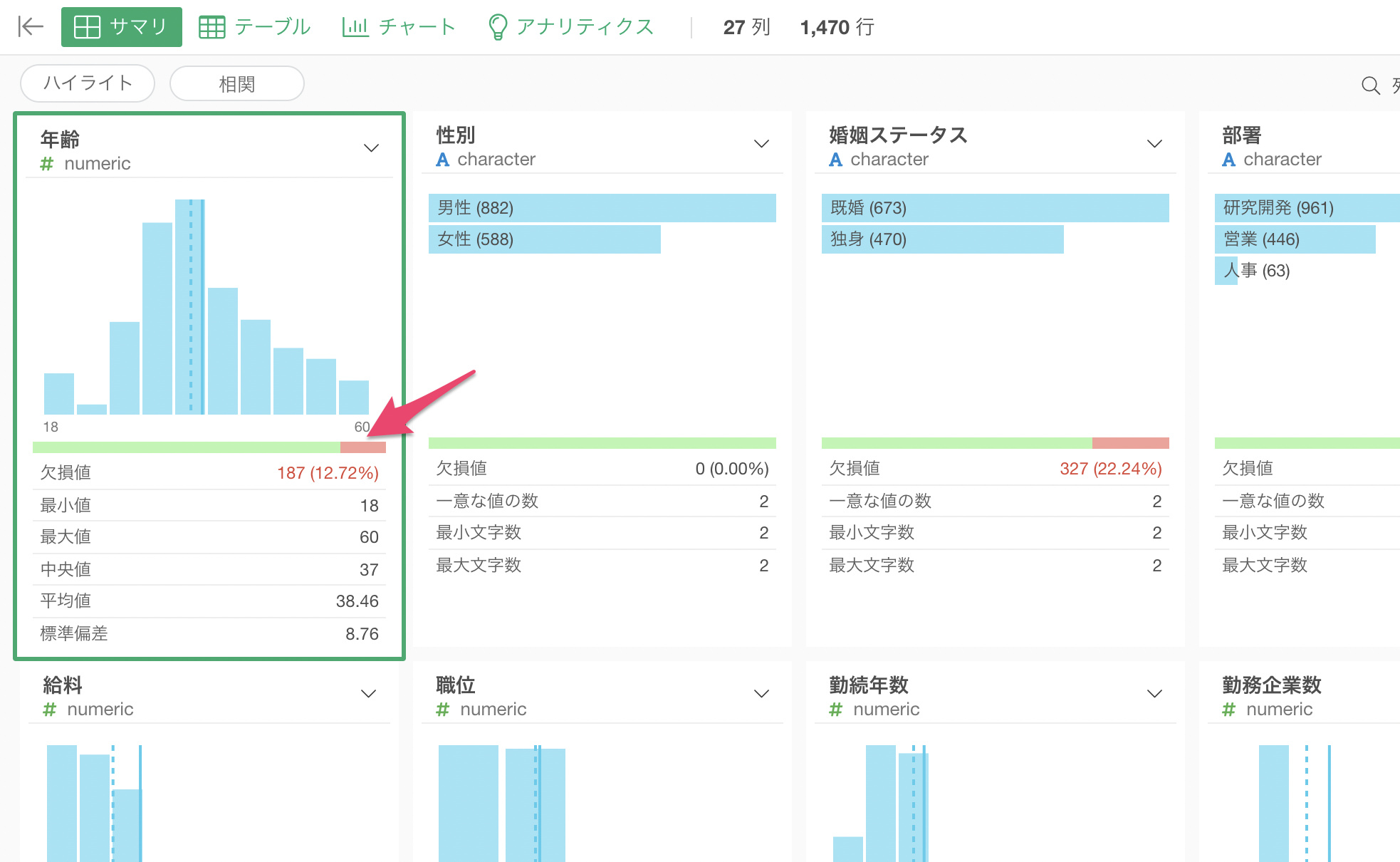
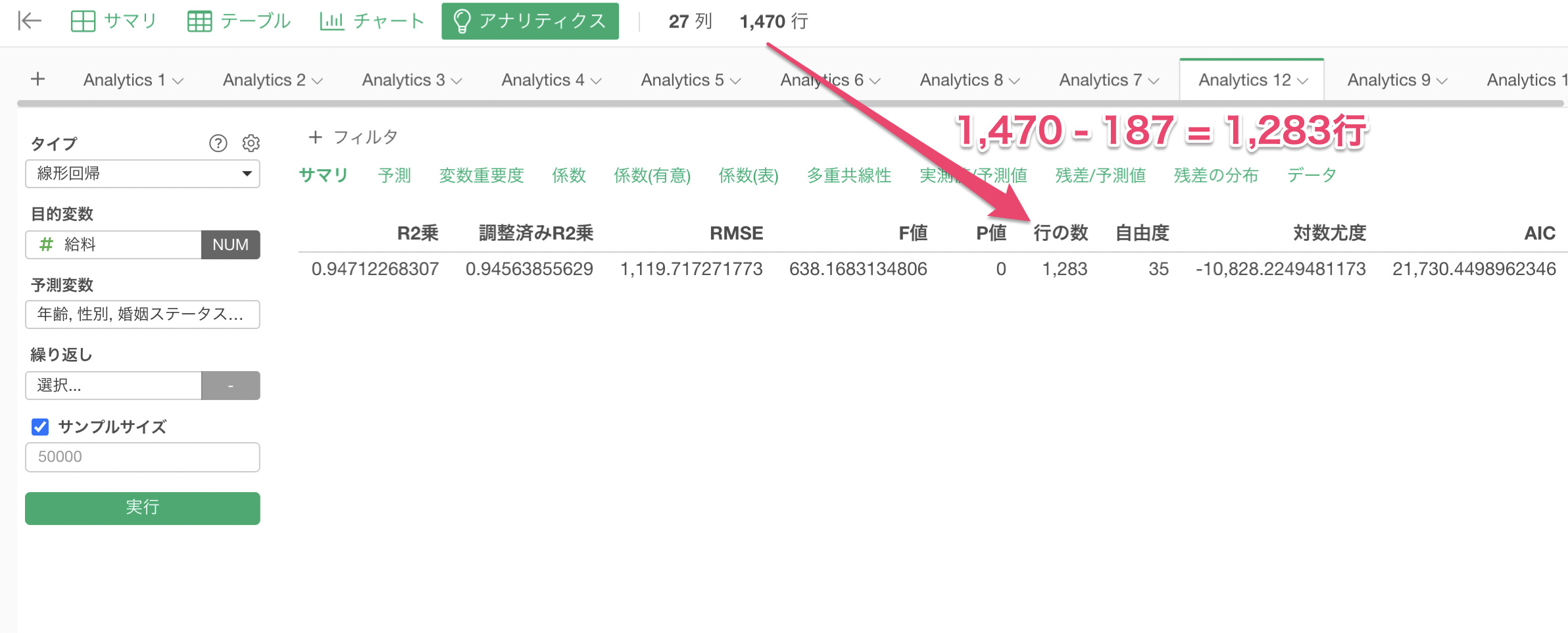
予測変数に年齢を割り当てて線形回帰を実行したところ、モデルで使用している行の数はデータ全体の行の数である1,470行ではなく、187行を引いた「1,283行」になります。
予測変数がカテゴリーの場合
Exploratoryではカテゴリー列のデータの中に欠損値があると、欠損値というカテゴリー値として扱うことになります。
例えば、カテゴリー型の列である婚姻ステータスの列に欠損値があったとします。
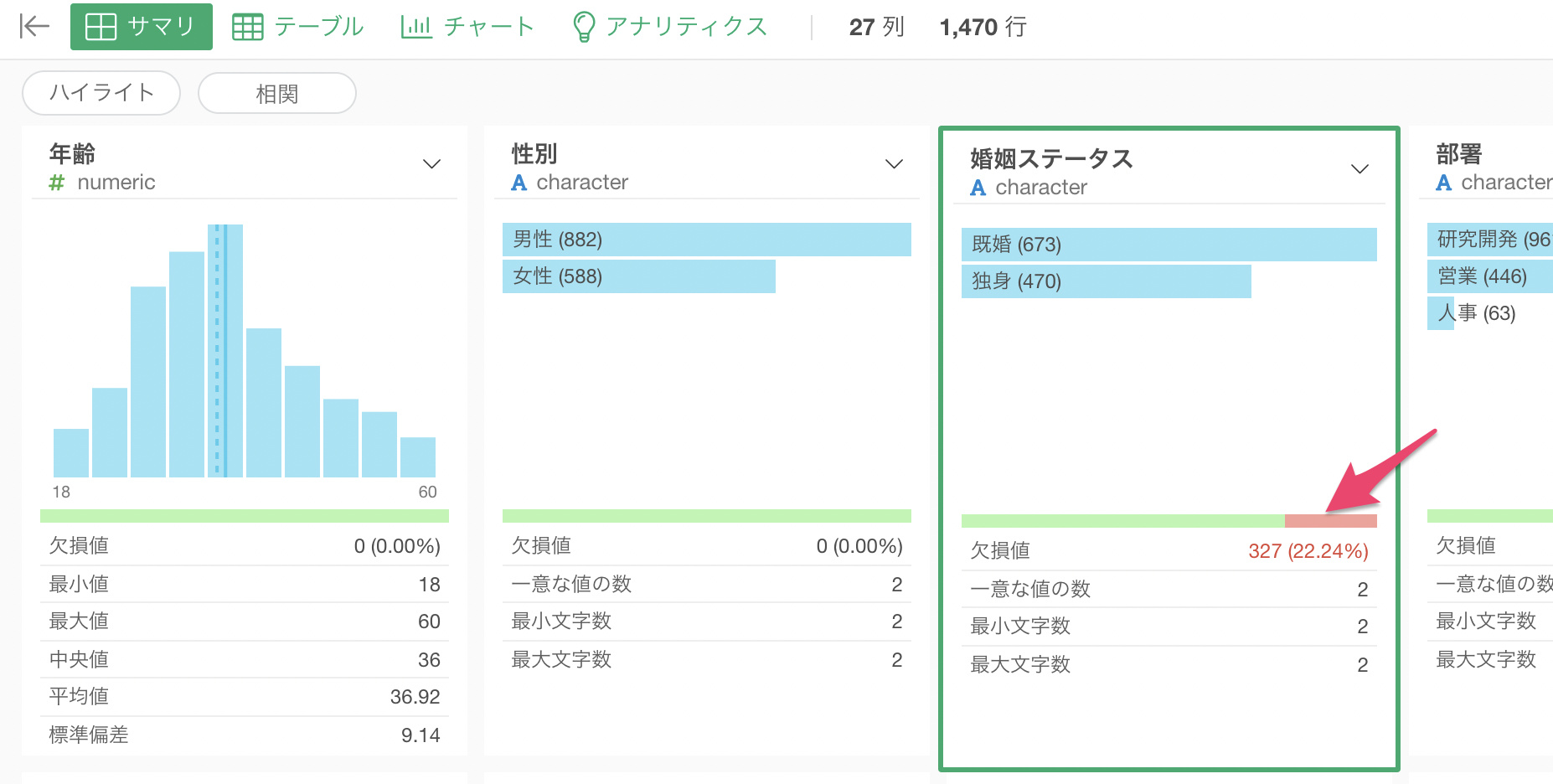
カテゴリー列の欠損値の場合は、下記のように欠損値(Missing)というカテゴリー値として扱われます。
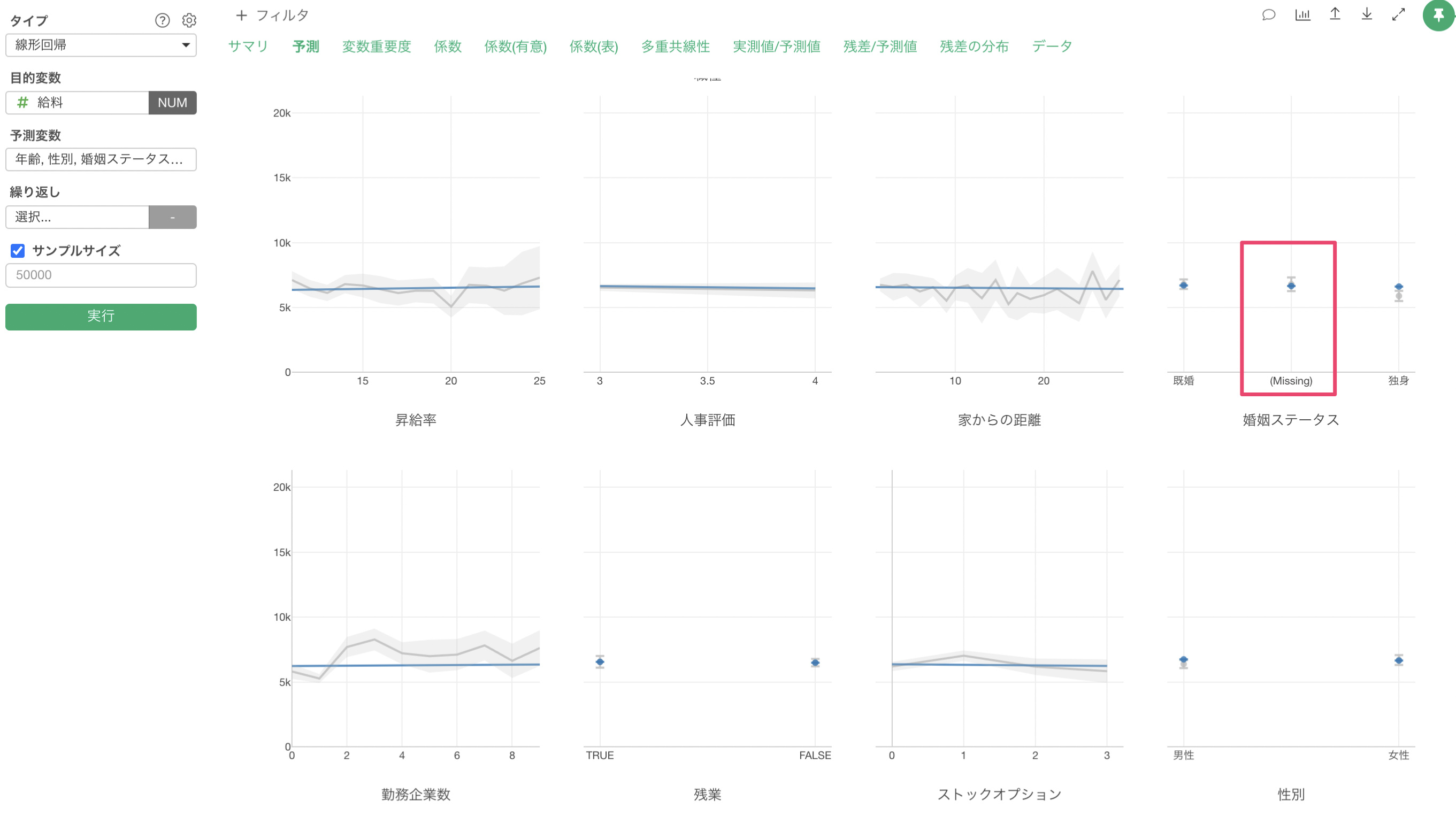
これらの欠損値の扱いが他のツールと異なる場合は、R2乗に違いが出る可能性があります。