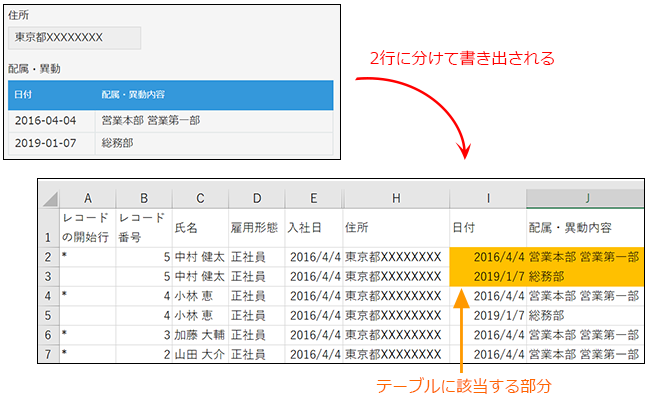
会社でkintoneを使っております。
kintoneの(サブ)テーブルを持ったデータを登録・更新するためには、上記のように繰り返しの項目も含めて縦にレコードを並べ、重複レコードの先頭に印(「*」)をつける必要があるのですが、Exploratoryではどのようにしたら実現できますでしょうか?
なんとなく、グループ化の後にインデックスを付ける→インデックスの1を「*」に置換すればいけるように思いましたが、、、。
PowerQueryによる方法:
会社でkintoneを使っております。
kintoneの(サブ)テーブルを持ったデータを登録・更新するためには、上記のように繰り返しの項目も含めて縦にレコードを並べ、重複レコードの先頭に印(「*」)をつける必要があるのですが、Exploratoryではどのようにしたら実現できますでしょうか?
なんとなく、グループ化の後にインデックスを付ける→インデックスの1を「*」に置換すればいけるように思いましたが、、、。
PowerQueryによる方法:
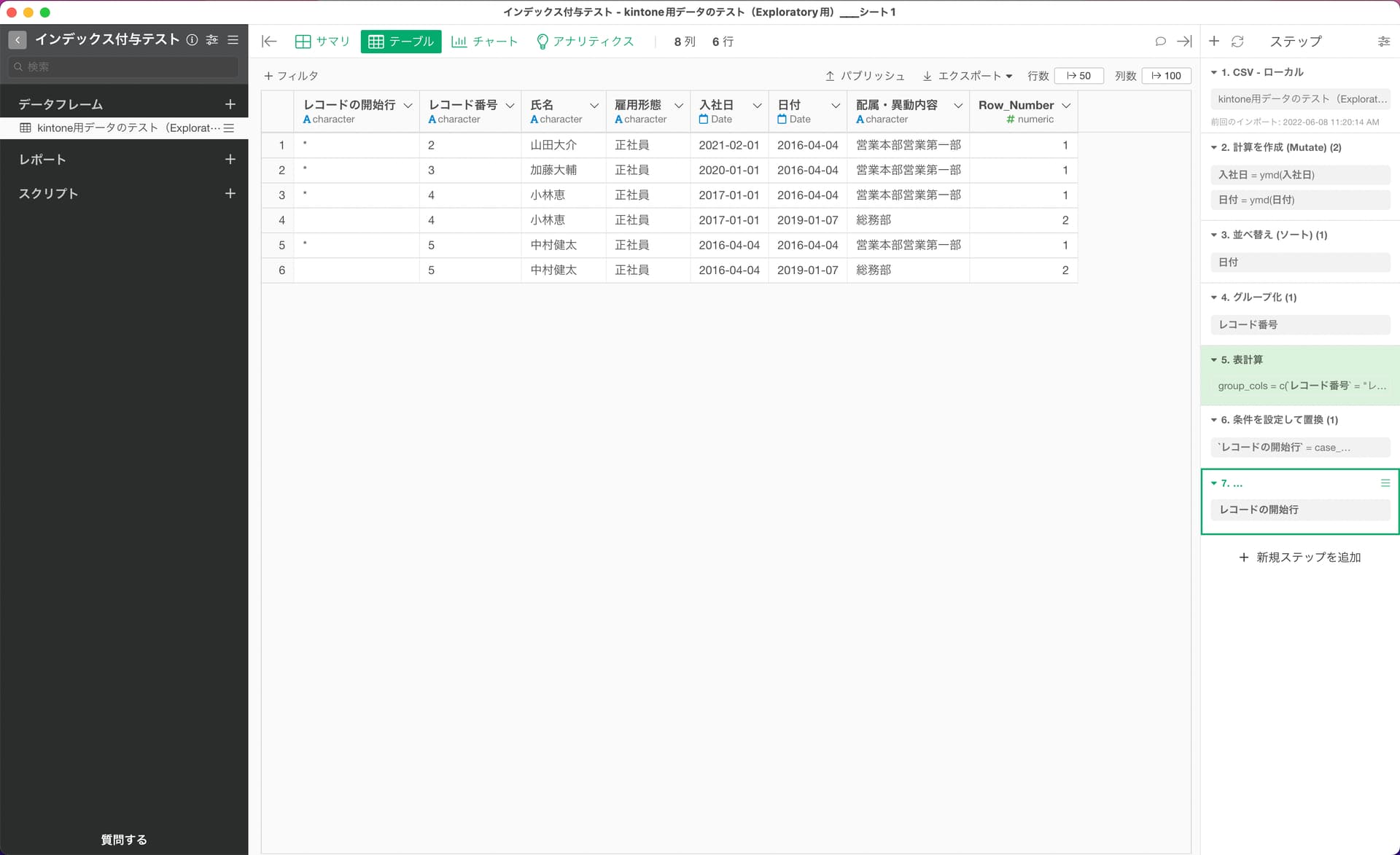
すみません、自己解決しました。
# Set libPaths.
.libPaths("/Users/hayashitomohiko/Documents/Exploratory2/R/4.1_ARM")
# Load required packages.
library(janitor)
library(lubridate)
library(hms)
library(tidyr)
library(stringr)
library(readr)
library(cpp11)
library(forcats)
library(RcppRoll)
library(dplyr)
library(tibble)
library(bit64)
library(zipangu)
library(exploratory)
# Steps to produce the output
exploratory::read_delim_file("/Users/hayashitomohiko/Downloads/kintone用データのテスト(Exploratory用) - シート1.csv", delim = ",", quote = "\"" , col_names = TRUE , na = c('') , locale=readr::locale(encoding = "UTF-8", decimal_mark = ".", tz = "Asia/Tokyo", grouping_mark = "," ), trim_ws = TRUE, col_types = cols(入社日 = "c", レコード番号 = "c", .default="?") , progress = FALSE) %>%
readr::type_convert() %>%
exploratory::clean_data_frame() %>%
mutate(入社日 = ymd(入社日), 日付 = ymd(日付)) %>%
arrange(日付) %>%
group_by(レコード番号) %>%
mutate_group(group_cols = c(`レコード番号` = "レコード番号"),group_funs = c("none"),Row_Number = row_number()) %>%
mutate(`レコードの開始行` = case_when(Row_Number == 1 ~ "*" , TRUE ~ "")) %>%
reorder_cols(レコードの開始行)
こちらを参考にさせていただきました。
https://ja.exploratory.io/note/GMq1Qom5tS/Exploratory-Hour-82-Uzq3FJm6sj