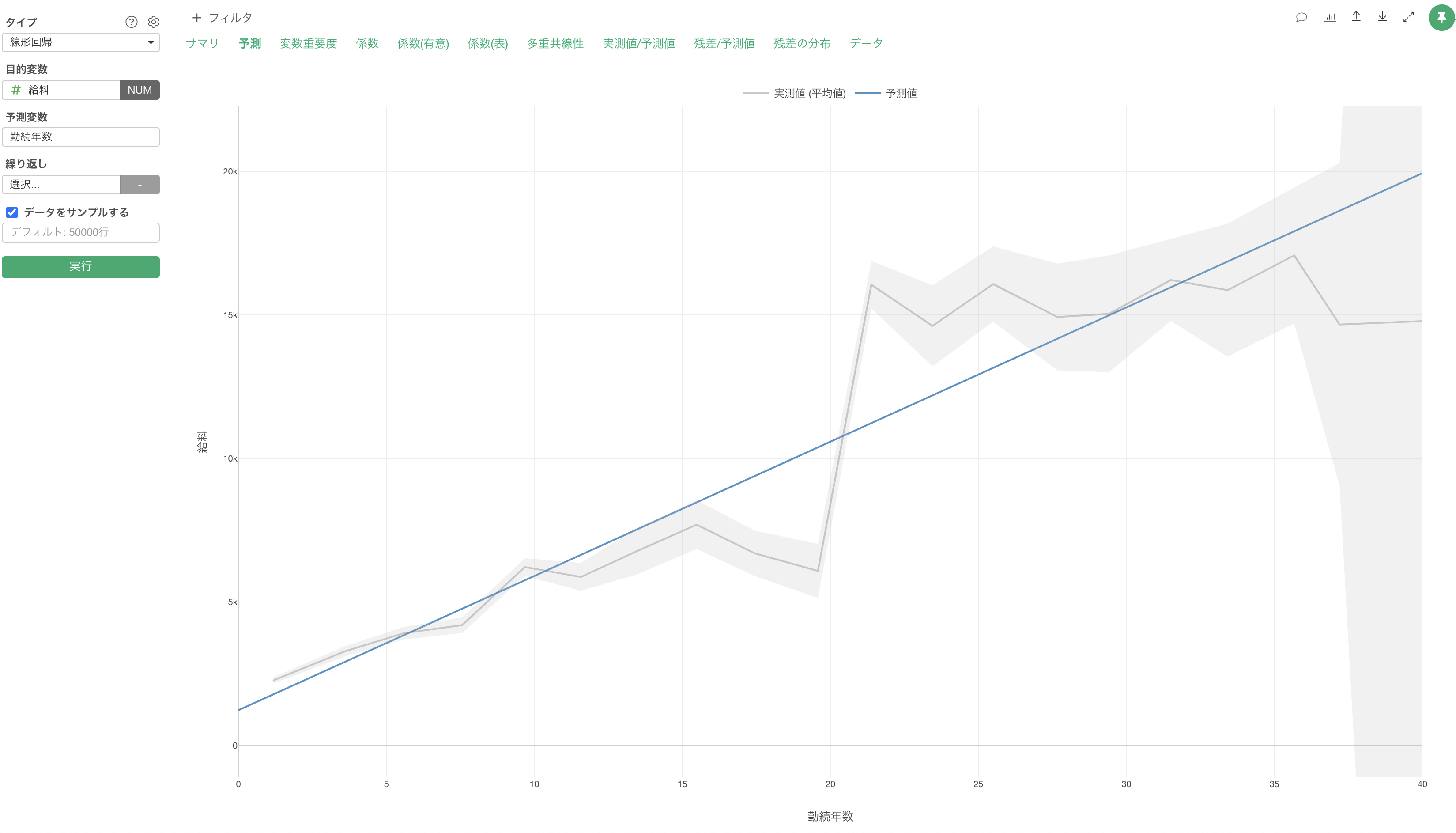
線形回帰などの統計の予測モデルで、予測変数が一つの時は「単回帰」と呼びます。
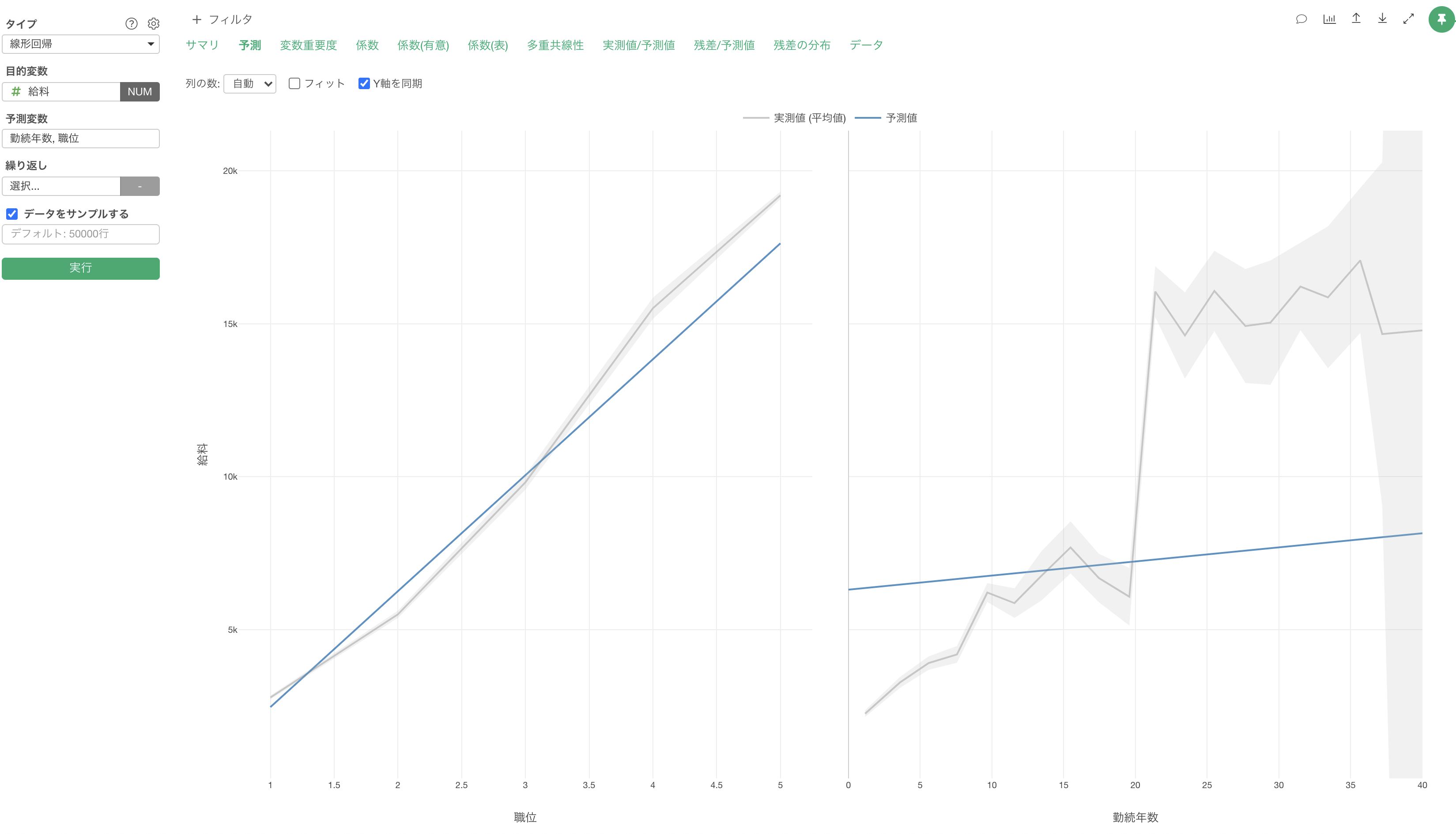
予測変数が複数の時は「重回帰」と呼ばれます。
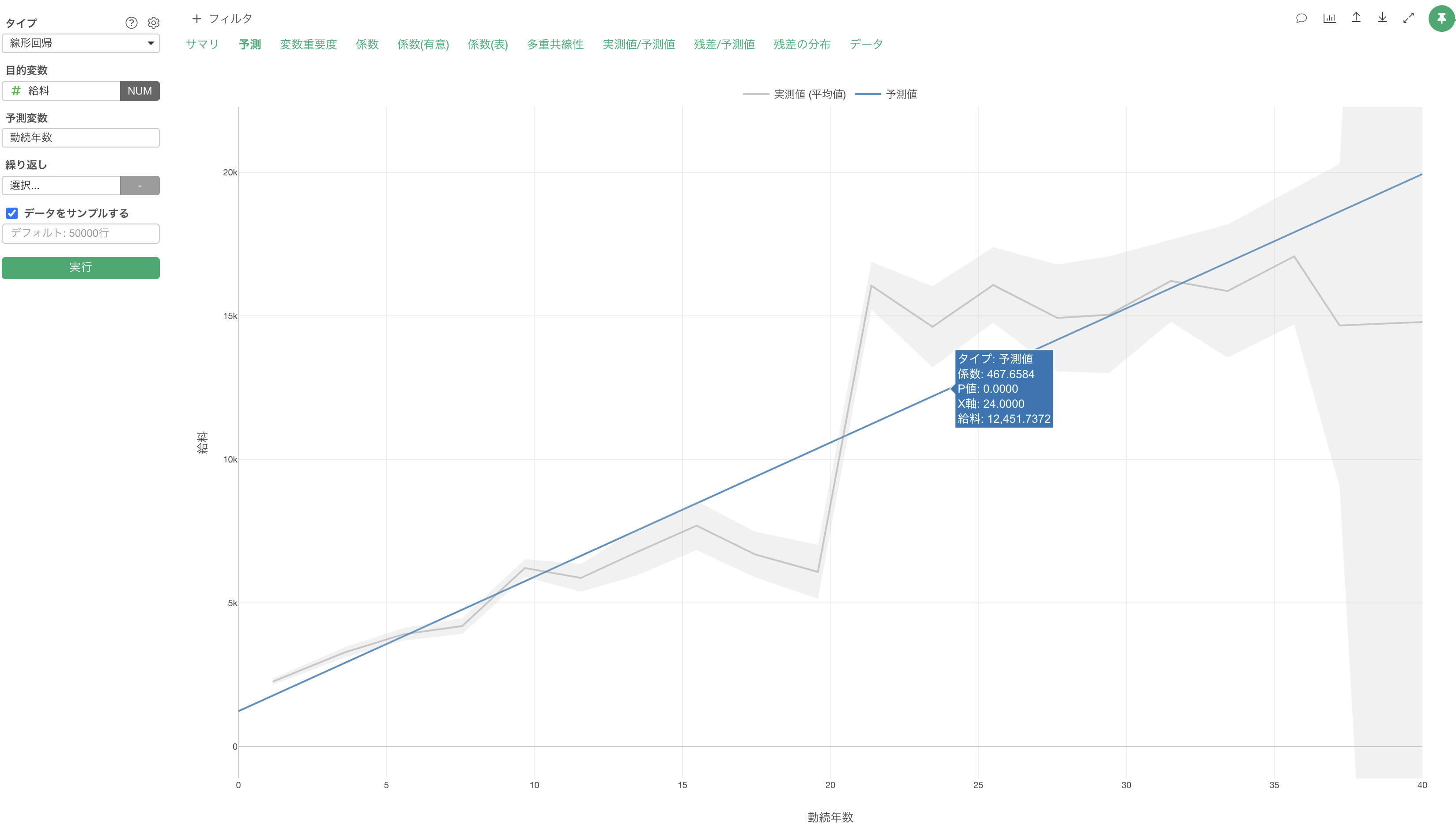
例えば、「給料」を予測する線形回帰のモデルを作成した際に、予測変数に「勤続年数」だけを割り当てた「単回帰」の時は、勤続年数の傾き(係数)は468ドル程となります。
しかし、予測変数に「勤続年数」と「職位」を割り当てた「重回帰」の時は、勤続年数の傾き(係数)は46ドル程となり、傾きに違いがあることがわかります。
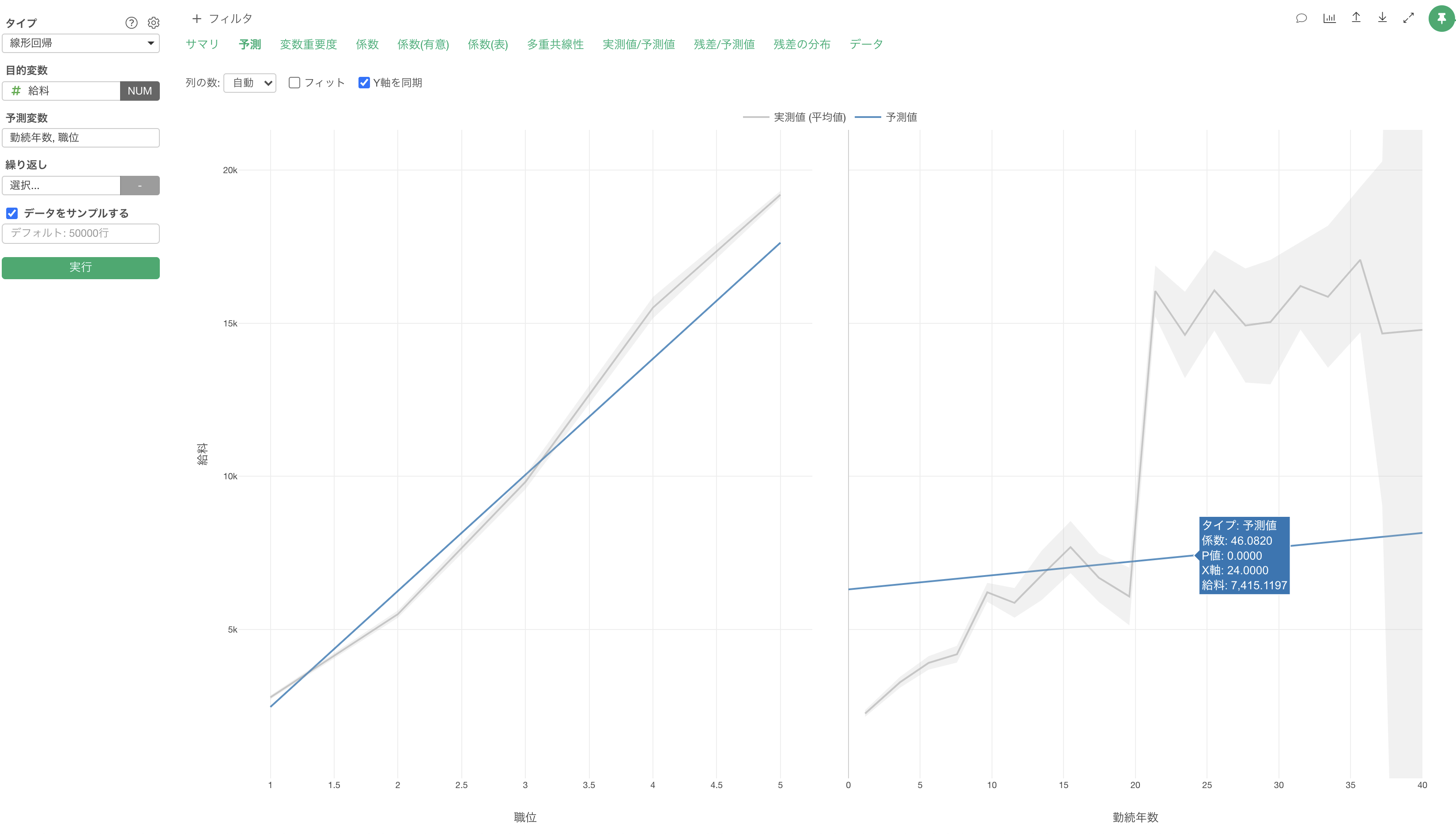
線形回帰で予測変数に複数の列を割り当てた「重回帰」の時には、他の変数を固定した上で、その変数での効果が出るようになります。つまりは、他の変数の効果を除いて、その変数だけの効果が見れるようになっています。
もし、予測変数が一つしかない「単回帰」の場合は、その変数が他の変数の効果を内包している可能性があります。上記の例では、「勤続年数」は「職位」と相関関係があったために、「勤続年数」単体だと職位の効果も内包していたということになります。
何が本当に関係しているのかを知りたい場合には、予測変数に複数の列を割り当てた方が、どの変数が重要なのか、それはどういった予測(効果)があるのかを調べていくことができます。