クラスター内平方和は各クラスターの中心地からのそれぞれのデータのずれの合計だと捉えていただければと思います。この値が小さければ小さいほどずれが少なくなり、K-Meansではこのクラスター内平方和を少なくするために、クラスターの中心となる点をずらしていくという手法となっています。
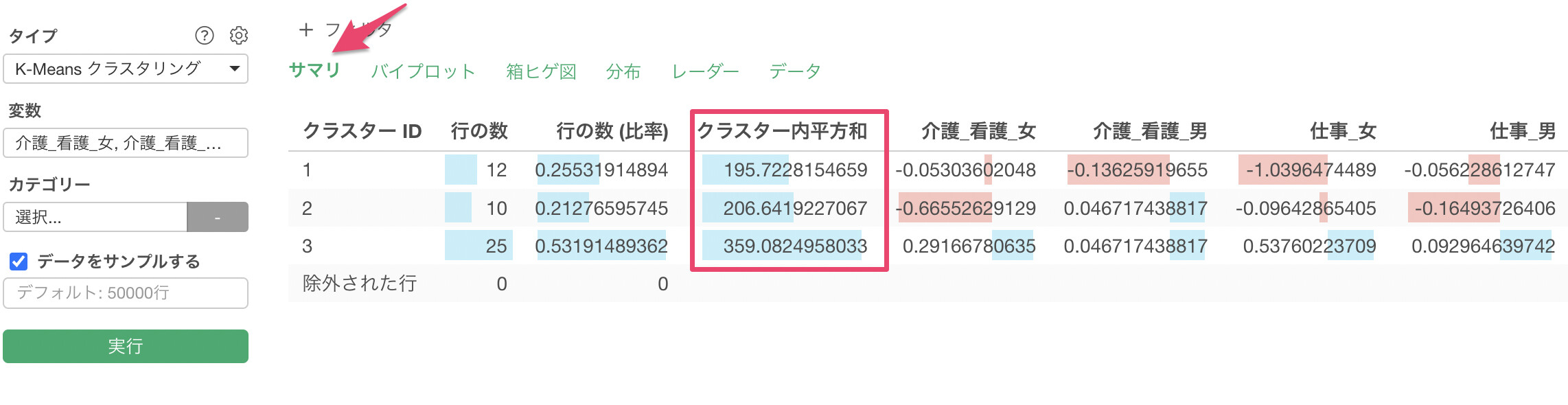
クラスター内平方和は各クラスターの中心地からのそれぞれのデータのずれの合計だと捉えていただければと思います。この値が小さければ小さいほどずれが少なくなり、K-Meansではこのクラスター内平方和を少なくするために、クラスターの中心となる点をずらしていくという手法となっています。