例えば、下記のデータがあったとします。
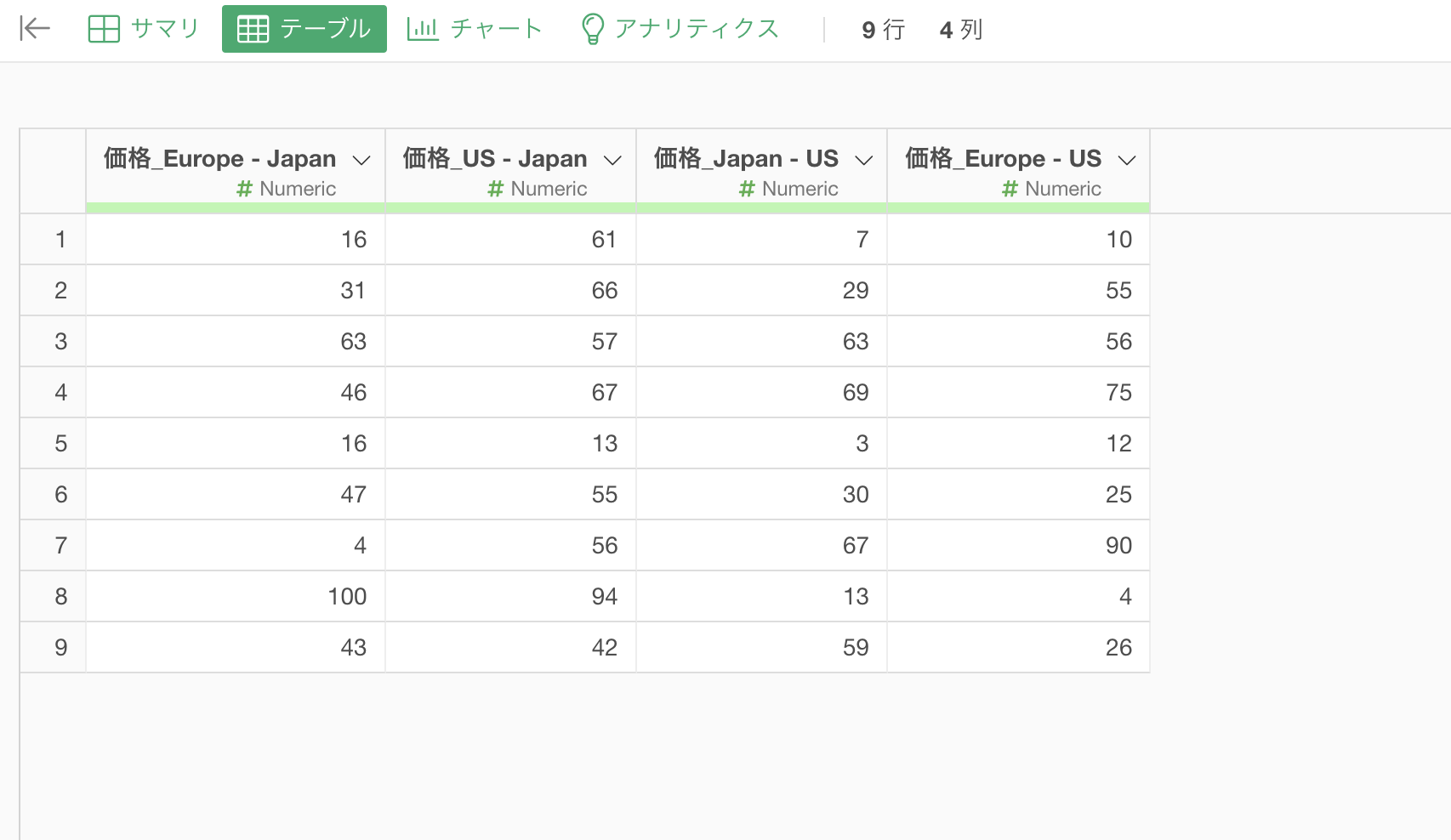
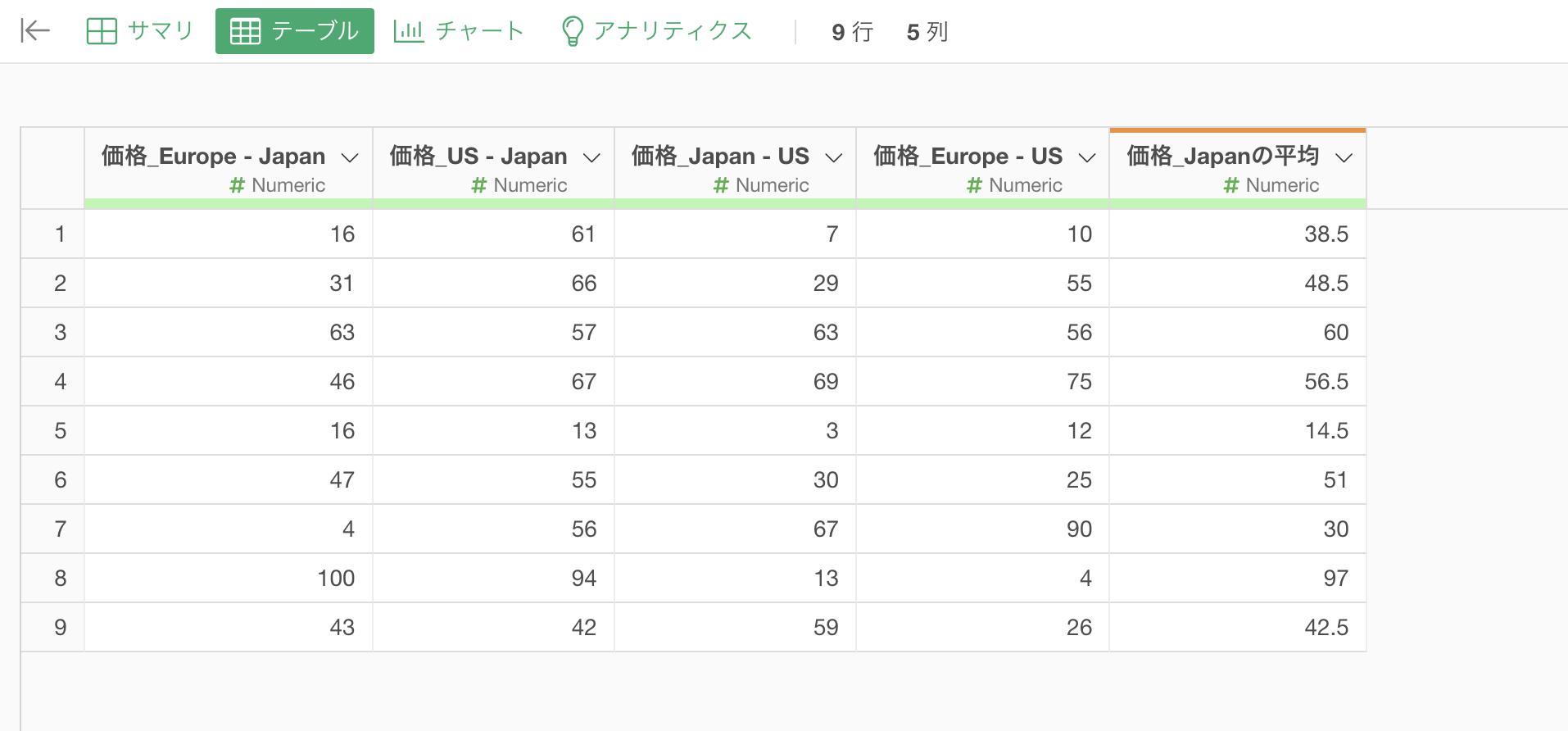
今回は、行ごとに「価格_Europe - Japan」と「価格_US - Japan」の列の平均値を求めたいとします。
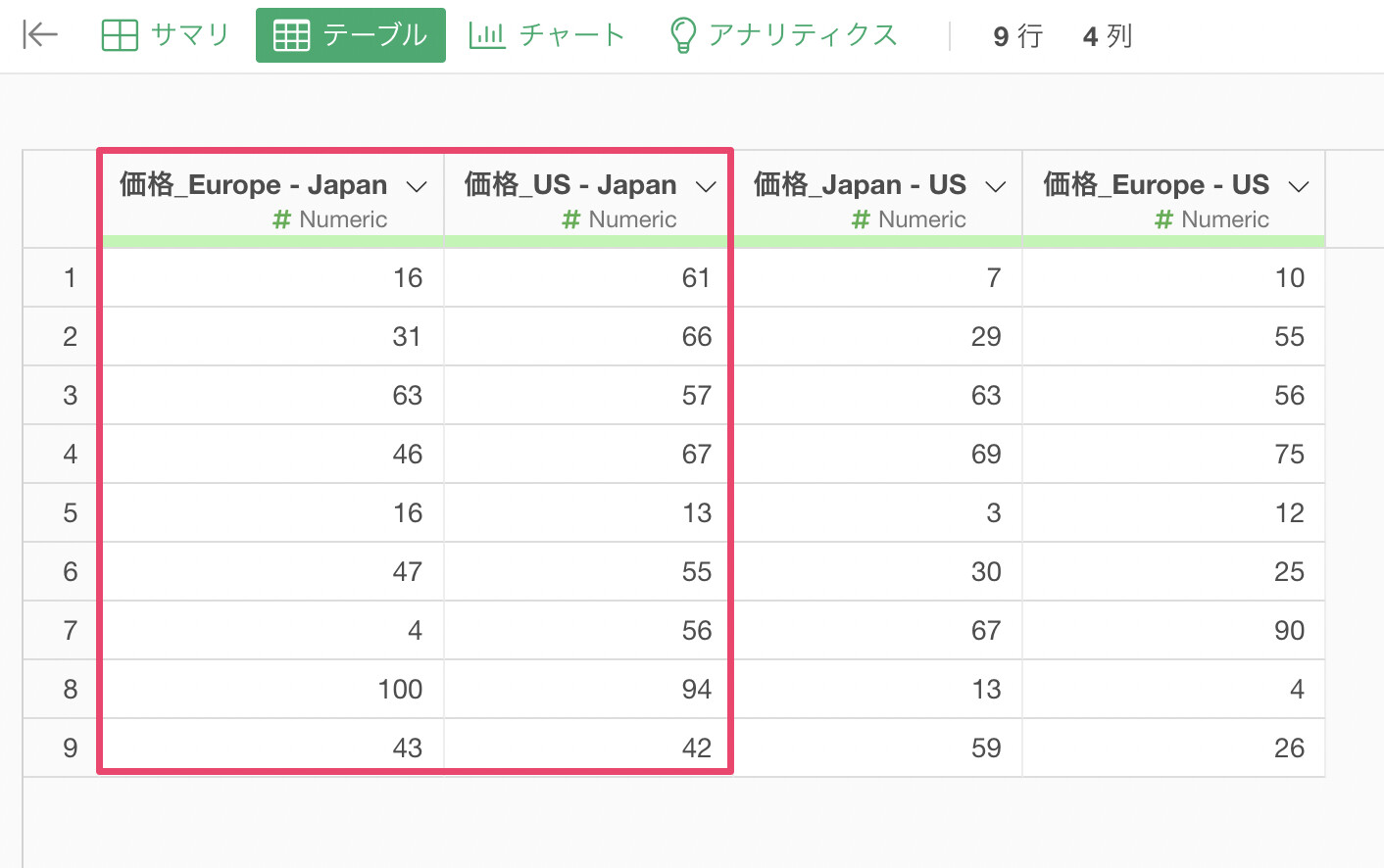
行ごとに「価格_Europe - Japan」と「価格_US - Japan」の列の平均値を求めたい時にはsummarize_rowといった関数が使えます。summarize_row関数についての詳細はこちらの動画をご覧ください。
このデータでは2つの列しかありませんが、他にも同様の列があった時に一気に選択するために、「価格_いずれかの複数の文字 - Japan」のパターンに該当する列を指定したいとしましょう。
では、このいずれかの複数の文字を指定するためにはどうしたら良いのでしょうか?
そこで使えるのが「正規表現」です。「正規表現」とはある特定の文字列のパターンを記号などを使って表す手法のことを言います。
例えば、正規表現を書くことで下記のように表現できます。
やりたいこと
価格_いずれかの複数の文字 - Japan
正規表現
価格_.* - Japan
価格_の後にある「.」と「*」が正規表現で、「.」はいずれかの文字、「*」は直前の文字を0回以上繰り返すという意味になります。
ではこの正規表現を使って、「価格_いずれかの複数の文字 - Japan」のパターンに該当する列の平均値を求めていきましょう。
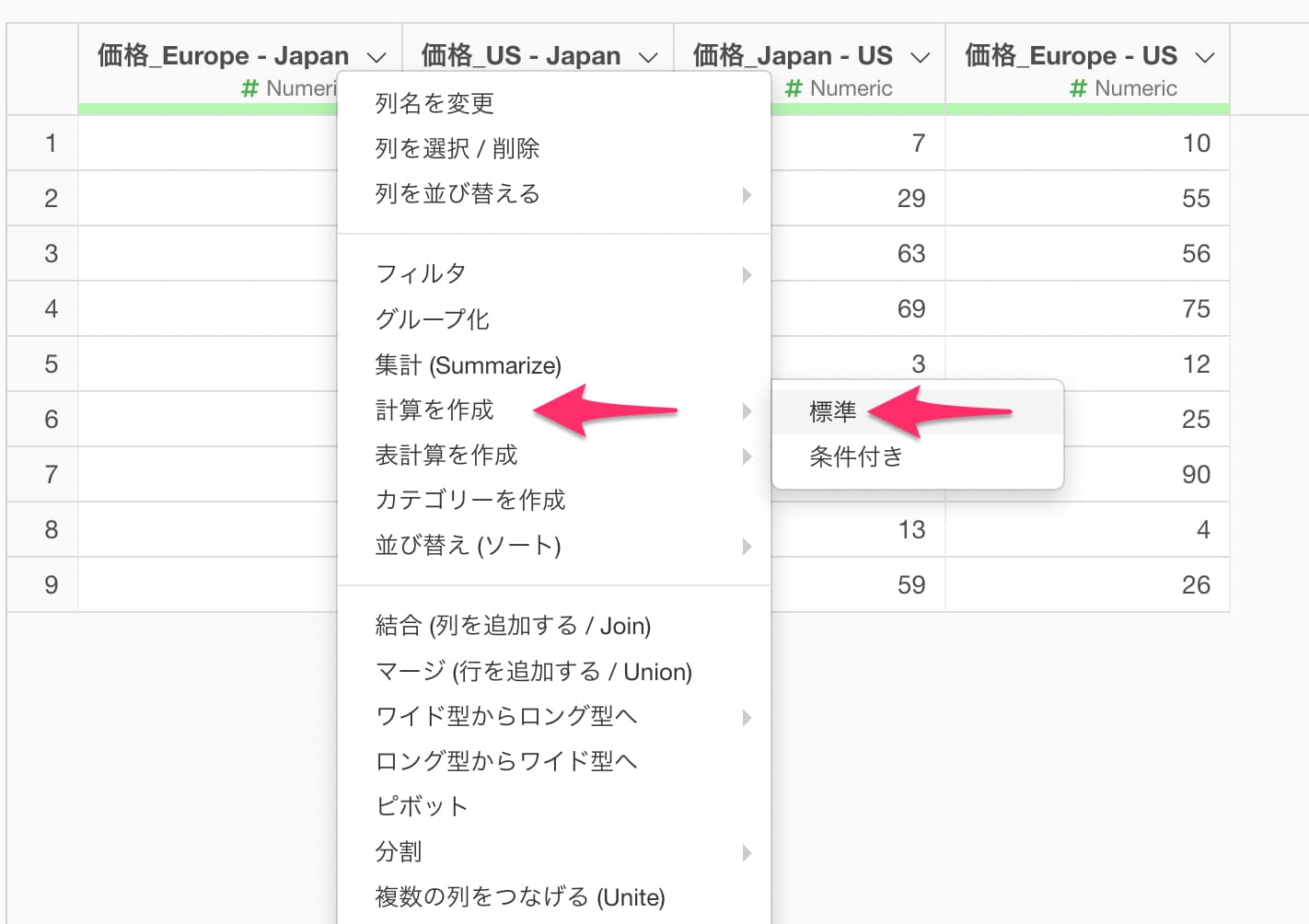
列ヘッダメニューから「計算を作成」の「標準」を選択します。
計算エディタには下記の式を入力します。
summarize_row(across(matches("価格_.* - Japan")), mean, na.rm=TRUE)
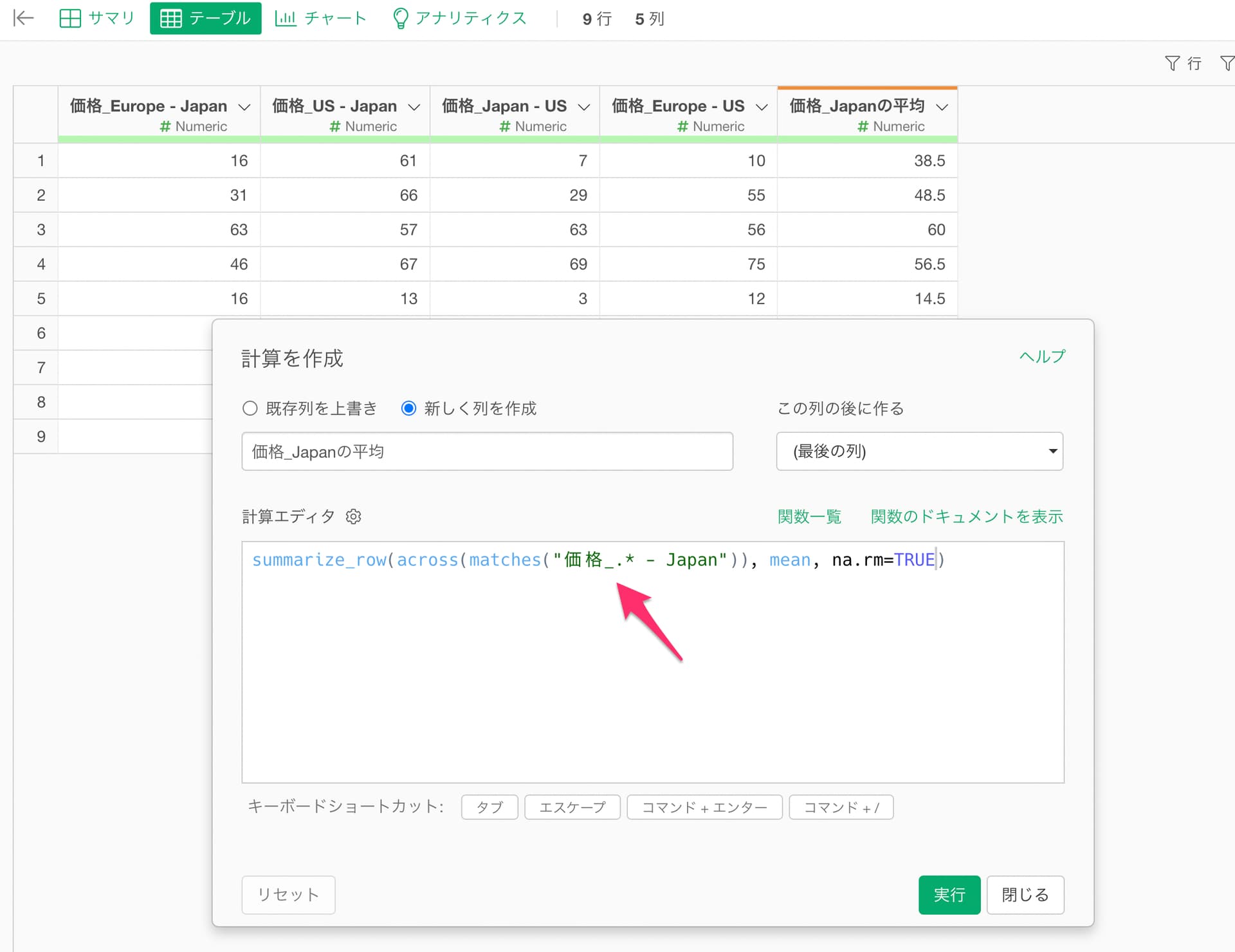
これにより、「価格_いずれかの複数の文字 - Japan」のパターンに該当する列の平均値を求めることができました。
最後に、正規表現について詳しく知りたい方はこちらの資料をご覧ください。